有了深度学习的基础之后,我们就可以训练或使用一些大型的网络了。接下来让我们看一下深度学习领域的“迁移学习”是什么样的吧!~
1. 期望目标
① 学习使用 PyTorch 的数据集套件从本地加载数据的方法
② 迁移训练好的大型神经网络模型实现自己个性目标的方法
③ 迁移学习与普通深度学习方法的区别及不同迁移学习方式的区别
2. 从本地文件中加载训练数据
2-1. 引入相关包
# 加载程序所需要的包
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import copy
import os
# 去除警告
import warnings
warnings.filterwarnings("ignore")2-2. 从硬盘文件夹中加载图像数据集
这里我们需要注意的是,使用 PyTorch 加载本地数据集时,可以使用相对路径,也可以使用绝对路径。例如:将数据集文件夹beeabt_data放到当前工程文件夹里的/数据集/4.迁移学习里面,那么我们就可以使用如下方法加载数据到内存中。顺便可以加入一些数据增强操作。
# 加载需要的数据
data_dir = './数据集/4.迁移学习/beeant_data'
# 要将图像转换为 224×224 像素
image_size = 224
# 从 data_dir/train 中加载文件
# 加载的过程将会对图像进行如下图像增强操作:
# 1. 随机从原始图像中切下来一块 224×224 大小的区域
# 2. 随机水平翻转图像
# 3. 将图像的色彩数值标准化
train_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'),
transforms.Compose([
transforms.RandomSizedCrop(image_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
)
# 加载校验数据集,对每个加载的数据进行如下处理:
# 1. 放大到 256×256 像素
# 2. 从中心区域切割下 224×224 大小的图像区域
# 3. 将图像的色彩数值标准化
val_dataset = datasets.ImageFolder(os.path.join(data_dir, 'val'),
transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229,0.224,0.225])
])
)
# 创建相应的数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=4, shuffle=True, num_workers=0)
# 读取数据中的分类类别数
num_classes = len(train_dataset.classes)
2-3. 启用 GPU 运算(没有时自动调用 CPU )
# 建立布尔变量,判断是否可以用 GPU
use_cuda = torch.cuda.is_available()
use_cudaTrue
# 如果可以用 GPU ,则设定 Tensor 的变量类型支持 GPU
dtype = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
itype = torch.cuda.LongTensor if use_cuda else torch.LongTensor
2-4. 查看并绘制数据集中的图片
# 定义查看并绘制数据集中图片的函数 imshow()
def imshow(inp, title=None):
# 将一张图像打印显示出来,inp为一个张量,title为显示在图像上的文字
# PyTorch 张量需要加载的图像格式为:通道数 × 图像宽度 × 图像高度
# 一般图像格式为:图像宽度 × 图像高度 × 通道数(Paddle直接这样定义张量)
inp = inp.numpy().transpose((1, 2, 0)) #转化 Tensor 中的 channels 到最后一个维度
# 由于在读取图像时,所有图像的色彩都标准化了,要想显示出来需要调节回去
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
# 绘制图像
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 绘制第一个 batch 和标签
images, labels = next(iter(train_loader))
# 将这个 batch 中的图像制成表格绘制出来
out = torchvision.utils.make_grid(images)
plt.figure(figsize=(15,15))
imshow(out, title=[train_dataset.classes[x] for x in labels]) 
3. 模型参照:训练一个普通的卷积神经网络
3-1. 建立模型架构
# 定义卷积神经网络:4 和 8 为人为指定的两个卷积层的厚度( feature map 的数量)
depth = [4, 8]
class ConvNet(nn.Module):
def __init__(self):
# 该函数在创建一个 ConvNet 对象即调用语句 net=ConvNet() 时就会被调用
# 首先调用父类相应的构造函数
super(ConvNet, self).__init__()
# 其次构造 ConvNet 需要用到的各个神经模块
# 注意,定义组件并不是真正搭建组件,只是把基本建筑砖块先找好
# 定义一个卷积层,输入通道为 3,输出通道为 4,窗口大小为 5,padding为 2
self.conv1 = nn.Conv2d(3, 4, 5, padding = 2)
self.pool = nn.MaxPool2d(2, 2) #定义一个池化层,一个窗口为2x2的池化运算
# 第二层卷积,输入通道为 depth[0],输出通道为 depth[1],窗口为 5,padding 为 2
self.conv2 = nn.Conv2d(depth[0], depth[1], 5, padding=2)
# 一个线性连接层,输入尺寸为最后一层立方体的线性平铺,输出层 512 个节点
self.fc1 = nn.Linear(image_size // 4 * image_size // 4 * depth[1], 512)
self.fc2 = nn.Linear(512, num_classes) #最后一层线性分类单元,输入为 512,输出为要做分类的类别数
# 定义完成神经网络真正的前向运算,在这里把各个组件进行实际的拼装
def forward(self, x):
# 目前x的尺寸:(batch_size, image_channels, image_width, image_height)
x = self.conv1(x) #第一层卷积
x = F.relu(x) #激活函数用ReLU,防止过拟合
# 目前x的尺寸:(batch_size, num_filters, image_width, image_height)
x = self.pool(x) #第二层池化,将图片缩小
# 目前x的尺寸:(batch_size, depth[0], image_width/2, image_height/2)
x = self.conv2(x) #第三层又是卷积,窗口为 5,输入输出通道分别为 depth[0]=4, depth[1]=8
x = F.relu(x) #非线性函数
# 目前x的尺寸:(batch_size, depth[1], image_width/2,image_height/2)
x = self.pool(x)#第四层池化,将图片缩小到原来的1/4
# 目前x的尺寸:(batch_size, depth[1], image_width/4, image_height/4)
# 将立体的特征图 tensor 压成一个一维的向量
# view 函数可以将一个 tensor 按指定的方式重新排布
# 下面这个命令就是要让x按照 batch_size * (image_size//4)^2 * depth[1] 的方式来排布向量
x = x.view(-1, image_size // 4 * image_size // 4 * depth[1])
# 目前x的尺寸:(batch_size, depth[1]*image_width/4*image_height/4)
x = F.relu(self.fc1(x)) #第五层为全连接,ReLU激活函数
# 目前x的尺寸:(batch_size, 512)
# 以默认0.5的概率对这一层进行 dropout 操作,防止过拟合
x = F.dropout(x, training=self.training)
x = self.fc2(x) #全连接
# 目前x的尺寸:(batch_size, num_classes)
# 输出层为 log_softmax,即概率对数值 log(p(x)),采用 log_softmax 可以使后面的交叉熵计算更快
x = F.log_softmax(x, dim=1)
return x
3-2. 准备训练
# 自定义的计算一组数据分类准确度的函数
# prediction 为模型给出的预测结果,labels 为数据中的标签,比较二者以确定整个神经网络当前的表现
def rightness(predictions, labels):
# 计算预测错误率的函数、其中 predictions 是模型给出的一组预测结果,batch size行num classes列的
# 矩阵,labels是数据中的正确答案
# 对于任意一行(一个样本)的输出值的第1个维度求最大,得到每一行最大元素的下标
pred = torch.max(predictions.data, 1)[1]
# 将下标与labels中包含的类别进行比较,并累计得到比较正确的数量
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels) #返回正确的数量和这一次一共比较了多少元素# 加载网络
net = ConvNet()
# 如果 GPU 存在就把网络加载到 GPU 中
net = net.cuda() if use_cuda else net
criterion = nn.CrossEntropyLoss() #定义 Loss 函数
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)把训练模型和验证模型的语句封装成函数
# 训练模型
def train_model(data, target):
# 给网络模型做标记,标志说模型正在训练集上训练
# 这种区分主要是为了打开 net 的 training 标志
# 从而决定是否运行 dropout 与 batchNorm
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = rightness(output, target)
loss = loss.cpu() if use_cuda else loss
return right, loss
# 验证模型
def evaluation_model():
# 给网络模型做标记,标志说模型现在是验证模式
# 这种区分主要是为了关闭 net 的 training 标志
# 模型不会运行 dropout 与 batchNorm
net.eval()
vals = []
for data, target in val_loader:
data, target = Variable(data, requires_grad=True), Variable(target)
if use_cuda:
data, target = data.cuda(), target.cuda()
output = net(data)
val = rightness(output, target)
vals.append(val)
return vals3-3. 开始训练模型
record = []
# 开始训练循环
num_epochs = 20
net.train(True)
best_model = net
best_r = 0.0
for epoch in range(num_epochs):
train_rights = []
train_losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
if use_cuda:
data, target = data.cuda(), target.cuda()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = rightness(output, target)
train_rights.append(right)
loss = loss.cpu() if use_cuda else loss
train_losses.append(loss.data.numpy())
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
net.eval()
test_loss = 0
correct = 0
vals = []
for data, target in val_loader:
if use_cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, requires_grad=True), Variable(target)
output = net(data)
val = rightness(output, target)
vals.append(val)
val_r = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
###### 要在 GPU 训练,还需要转化这两个变量(看numpy版本而定) #######
val_r = torch.FloatTensor(val_r).cpu() if use_cuda else val_r
train_r = torch.FloatTensor(train_r).cpu() if use_cuda else train_r
#####################################################################
val_ratio = 1.0 * val_r[0].numpy() / val_r[1]
if val_ratio > best_r:
bast_r = val_ratio
best_model = copy.deepcopy(net)
print('训练周期:{} \tLoss:{:.6f} \t训练正确率:{:.2f}%,校验正确率:{:.2f}%'.format(
epoch, np.mean(train_losses),
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
record.append([np.mean(train_losses), 1. * train_r[0].data.numpy() / train_r[1], 1. * val_r[0].data.numpy() / val_r[1]])
训练周期:0 Loss:0.428622 训练正确率:79.51%,校验正确率:67.32%
训练周期:1 Loss:0.441055 训练正确率:79.92%,校验正确率:68.63%
训练周期:2 Loss:0.403215 训练正确率:81.56%,校验正确率:66.67%
训练周期:3 Loss:0.419026 训练正确率:80.74%,校验正确率:71.90%
训练周期:4 Loss:0.386414 训练正确率:80.74%,校验正确率:71.24%
训练周期:5 Loss:0.363576 训练正确率:83.20%,校验正确率:73.20%
训练周期:6 Loss:0.475404 训练正确率:78.28%,校验正确率:67.97%
训练周期:7 Loss:0.373927 训练正确率:82.79%,校验正确率:71.24%
训练周期:8 Loss:0.415344 训练正确率:80.33%,校验正确率:69.28%
训练周期:9 Loss:0.376967 训练正确率:81.56%,校验正确率:69.28%
训练周期:10 Loss:0.410114 训练正确率:83.61%,校验正确率:68.63%
训练周期:11 Loss:0.393242 训练正确率:81.97%,校验正确率:69.93%
训练周期:12 Loss:0.422198 训练正确率:80.33%,校验正确率:72.55%
训练周期:13 Loss:0.380430 训练正确率:84.02%,校验正确率:71.24%
训练周期:14 Loss:0.396315 训练正确率:82.38%,校验正确率:71.24%
训练周期:15 Loss:0.370933 训练正确率:82.38%,校验正确率:68.63%
训练周期:16 Loss:0.402982 训练正确率:79.51%,校验正确率:69.28%
训练周期:17 Loss:0.384442 训练正确率:80.74%,校验正确率:71.24%
训练周期:18 Loss:0.394311 训练正确率:82.38%,校验正确率:70.59%
训练周期:19 Loss:0.395228 训练正确率:83.61%,校验正确率:67.32%本机(EzXxY PC) GPU 2 分钟内即可完成这 20 轮训练,若用 CPU 预计需要 45 分钟
3-4. 训练效果展示
# 在测试集上分批运行,并计算总的正确率
net.eval() #模型当前为校验阶段
test_loss = 0
correct = 0
vals = []
# 对测试集进行循环
for data, target in val_loader:
data, target = Variable(data, requires_grad=True), Variable(target)
if use_cuda:
data, target = data.cuda(), target.cuda()
output = net(data)
val = rightness(output, target)
vals.append(val)
rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
############# 要在 GPU 训练,还需要转化这个变量 #################
rights = torch.FloatTensor(rights).cpu() if use_cuda else rights
#################################################################
right_rate = 1.0 * rights[0].data.numpy() / rights[1]
right_rate
tensor(0.6732)
事实表明,这种简单结构的卷积神经网络并不能将蚂蚁和蜜蜂这种复杂的图片分类正确,正确率勉强能达到 67% 上下,只能说是刚及格。
为什么模型预测的效果那么差?
究其原因,是在于:
1.蚂蚁和蜜蜂的图像数据极其复杂,人类肉眼都不太容易一下子区分,因此简单的 CNN 无法应付这个分类任务
2.整个训练数据集仅仅有 244 个训练样本,这么小的数据量是无法训练大的卷积神经网络的
仍然观察一下模型的训练误差曲线
# 绘制误差率曲线
x = [x[0] for x in record]
y = [1-x[1] for x in record]
z = [1-x[2] for x in record]
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练周期', size=15)
plt.ylabel('错误率', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC', size=18)
Text(0.5, 1.0, 'EzXxY PC')

可以观察到模型的训练过程是非常的不稳定的,或许延长训练周期,增加神经网络深度可以让模型预测更加精确?先来看一下迁移学习能够达到怎样的效果吧。
4. 加载已训练好的 ResNet 进行迁移学习
4-1. 加载已训练的大型神经网络 ResNet
ResNet 是微软亚洲研究院何凯明团队开发的一种极深的特殊的卷积神经网络。该网络的原始版本曾号称是“史上最深的网络”,有 152 层,在物体分类等任务上具有较高的准确度。一般的,深度网络模型在层数过多时往往会表现得更差。那么,为什么 ResNet 可以做得如此之深呢?秘诀就在把每两个相邻的 CNN 模块(block)之间加上了一条捷径(shortcut)。
单个 ResNet 模块的结构如下图所示:
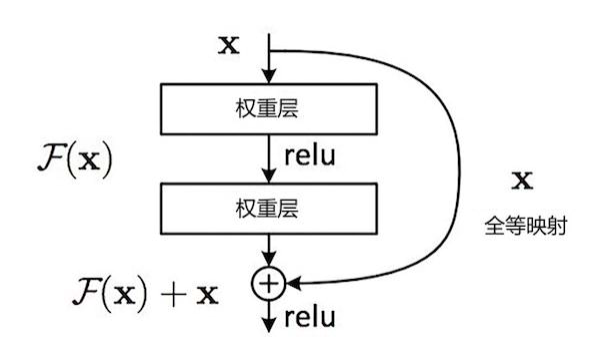
这个“捷径”将第一个模块的输入和第二个模块的输出连接到了一起,并与模块的输出进行张量求和,从而将这两个模块“短路”。这样做的好处就是大大提高了学习的效率,从而可以使得网络可以变得非常深,但是效果却不会下降。考虑到原始的 ResNet 具有较大的复杂性,在本次文中,实际迁移的是一个具有18 层的精简版的 ResNet。该网络由 18 个串联在一起的卷积模块构成,其中每一个卷积模块都包括一层卷积一层池化。
下面将加载 ResNet 模型,并观察模型的组网结构。如果是第一次运行,那么模型会被下载到~/.torch/models/文件夹中。
# 加载 ResNet18 这个网络 并且
# 加载模型库中的 residual network,并设置 pretrained 为 True,这样便可加载相应的权重
net = models.resnet18(pretrained=True)
# 有 GPU 就将模型加载到 GPU 上
net = net.cuda() if use_cuda else net
# 打印网络架构
netResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
) 从模型的组网结构中,可以看到最后有一层全连接层,也就是(fc):Linear(in_features=512,out_features=1000)
下面就对它进行“外科手术”。
4-2. 构建迁移网络
下面把 ResNet18 中的卷积模块作为特征提取层迁移过来,用于提取局部特征。同时,将 ResNet18 中最后的全连接层(fc)替换,构建一个包含 512 个隐含节点的全连接层,后接两个结点的输出层,用于最后的分类输出。最终构建一个 20 层的深度网络。

"""
本段代码中,num_ftrs存储了 ResNet18 最后的全连接层的输入神经元个数。
事实上,该段代码所做的就是将原来的 ResNet18 最后两层全连接层拿掉,
替换成一个输出单元为 2 的全连接层,这就是 net.fc 。
之后,我们按照普通的方法定义损失函数和优化器。
因此,这个模型首先会利用 ResNet 预训练好的权重,提取输入图像中的重要特征,
之后,再利用 net.fc 这个线性层,根据输入特征进行分类。
"""
# 读取最后线性层的输入单元数,这是前面各层卷积提取到的特征数量
num_ftrs = net.fc.in_features
# 重新定义一个全新的线性层,它的输出为 2,原本是 1000
net.fc = nn.Linear(num_ftrs, 2)
# 如果存在 GPU 则将网络加载到 GPU 中
net.fc = net.fc.cuda() if use_cuda else net.fc
# 定义 Loss 函数
criterion = nn.CrossEntropyLoss()
# 将网络的所有参数放入优化器中
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)
4-3. 迁移学习的两种模式
搭建好了模型,下面就可以进行迁移学习模型的训练了,这里有个知识点需要注意。现在整个模型的前面大部分的结构都是 ResNet,最后两层被替换成了自定义的全连接层。在训练阶段,迁移过来的 ResNet 模块的结构和所有超参数都可以保持不变,但是权重参数则有可能被新的数据重新训练。
是否要更新这些旧模块的权重参数完全取决于我们采取的迁移学习方式,它主要包括有两种:
- 预训练模式;
- 固定值模式。
接下来,将分别应用预训练和固定值两种模式来对这个深度网络进行训练。
4-4. 预训练模式
在这种模式下,从 ResNet 迁移过来的权重视作新网络的初始权重,但是在训练的过程中则会被梯度下降算法改变数值。使用这种方式,既可以保留迁移过来的知识(已被编码到了权重中),又保证了足够灵活的适应性。使得迁移过来的知识可以通过新网络在新数据上的训练而灵活调整。
预训练模式的梯度传播示意图如下:

import timerecord = []
# 开始训练循环
num_epochs = 20
net.train(True)
best_model = net
best_r = 0.0
t1 = time.time()
for epoch in range(num_epochs):
train_rights = []
train_losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
if use_cuda:
data, target = data.cuda(), target.cuda()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = rightness(output, target)
train_rights.append(right)
loss = loss.cpu() if use_cuda else loss
train_losses.append(loss.data.numpy())
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
net.eval()
test_loss = 0
correct = 0
vals = []
for data, target in val_loader:
if use_cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, requires_grad=True), Variable(target)
output = net(data)
val = rightness(output, target)
vals.append(val)
val_r = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
############# 要在 GPU 训练,还需要转化这两个变量 ###################
val_r = torch.FloatTensor(val_r).cpu() if use_cuda else val_r
train_r = torch.FloatTensor(train_r).cpu() if use_cuda else train_r
#####################################################################
val_ratio = 1.0 * val_r[0].numpy() / val_r[1]
if val_ratio > best_r:
bast_r = val_ratio
best_model = copy.deepcopy(net)
print('训练周期:{} \tLoss:{:.6f} \t训练正确率:{:.2f}%,校验正确率:{:.2f}%'.format(
epoch, np.mean(train_losses),
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
record.append([np.mean(train_losses), 1. * train_r[0].data.numpy() / train_r[1], 1. * val_r[0].data.numpy() / val_r[1]])
t2 = time.time()
t2 - t1训练周期:0 Loss:0.261994 训练正确率:87.30%,校验正确率:92.81%
训练周期:1 Loss:0.029982 训练正确率:99.59%,校验正确率:94.77%
训练周期:2 Loss:0.012930 训练正确率:99.59%,校验正确率:92.81%
训练周期:3 Loss:0.021242 训练正确率:99.18%,校验正确率:95.42%
训练周期:4 Loss:0.014141 训练正确率:99.18%,校验正确率:93.46%
训练周期:5 Loss:0.006281 训练正确率:100.00%,校验正确率:95.42%
训练周期:6 Loss:0.019141 训练正确率:99.59%,校验正确率:93.46%
训练周期:7 Loss:0.007880 训练正确率:100.00%,校验正确率:95.42%
训练周期:8 Loss:0.008455 训练正确率:99.59%,校验正确率:94.12%
训练周期:9 Loss:0.024190 训练正确率:99.59%,校验正确率:91.50%
训练周期:10 Loss:0.024529 训练正确率:98.77%,校验正确率:94.12%
训练周期:11 Loss:0.017349 训练正确率:99.18%,校验正确率:95.42%
训练周期:12 Loss:0.005863 训练正确率:100.00%,校验正确率:93.46%
训练周期:13 Loss:0.007901 训练正确率:100.00%,校验正确率:94.77%
训练周期:14 Loss:0.006473 训练正确率:100.00%,校验正确率:94.12%
训练周期:15 Loss:0.005731 训练正确率:99.59%,校验正确率:95.42%
训练周期:16 Loss:0.037910 训练正确率:98.77%,校验正确率:92.81%
训练周期:17 Loss:0.010953 训练正确率:99.59%,校验正确率:94.12%
训练周期:18 Loss:0.008111 训练正确率:100.00%,校验正确率:94.12%
训练周期:19 Loss:0.011209 训练正确率:99.59%,校验正确率:94.12%绘制训练误差曲线,观察训练过程
# 绘制误差率曲线
x = [x[0] for x in record]
y = [1-x[1] for x in record]
z = [1-x[2] for x in record]
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练周期', size=15)
plt.ylabel('错误率', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC', size=18)
Text(0.5, 1.0, 'EzXxY PC')

将预训练的模型用于测试数据,并举例绘制出分类效果
def visualize_model(model, num_images=6):
images_so_far = 0
for i, data in enumerate(val_loader):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
if use_cuda:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
preds = preds.cpu().numpy() if use_cuda else preds.numpy()
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(2, num_images//2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(val_dataset.classes[preds[j]]))
imshow(data[0][j])
if images_so_far == num_images:
return
visualize_model(net)
plt.ioff()
plt.show()






4-5. 固定值模式
在这种模式下,迁移过来的部分网络在结构和权重上都保持固定的数值不会改变。训练过程仅针对迁移模块后面的全连接网络。当使用反向传播算法的时候,误差反传过程会在迁移模块中停止,从而不改变迁移模块中的权重数值。采用这种方式,可以很大程度的保留被迁移部分的知识不被破坏,对新信息的适应完全体现在迁移模块后面的全链接网络上。因此,它的灵活适应性会差一些。然而,由于迁移模块不需要信息,因此,需要调节的参数少了很多,学习的收敛速度也理应会更快。

要想让模型在固定值模式下训练,需要先锁定网络模型相关位置的参数。锁定的方法非常简单,只要把网络的梯度反传标志 requires_grad 设置为 False 就可以了。
# 加载模型库中的 residual network,并设置 pretrained 为 True,这样便可加载相应的权重
net = models.resnet18(pretrained=True)
# 有 GPU 就将模型加载到 GPU 上
net = net.cuda() if use_cuda else net
# 循环网络,将所有参数设为不更新梯度信息
for param in net.parameters():
param.requires_grad = False
# 将网络最后一层线性层替换掉
num_ftrs = net.fc.in_features
# 重新定义一个全新的线性层,它的输出为 2,原本是 1000
net.fc = nn.Linear(num_ftrs, 2)
# 如果存在 GPU 则将网络加载到 GPU 中
net.fc = net.fc.cuda() if use_cuda else net.fc
# 定义 Loss 函数
criterion = nn.CrossEntropyLoss()
# 将网络的所有参数放入优化器中
optimizer = optim.SGD(net.fc.parameters(), lr=0.0001, momentum=0.9)
正式开始训练
record = []
# 开始训练循环
num_epochs = 20
net.train(True)
best_model = net
best_r = 0.0
t1 = time.time()
for epoch in range(num_epochs):
train_rights = []
train_losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
if use_cuda:
data, target = data.cuda(), target.cuda()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = rightness(output, target)
train_rights.append(right)
loss = loss.cpu() if use_cuda else loss
train_losses.append(loss.data.numpy())
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
net.eval()
test_loss = 0
correct = 0
vals = []
for data, target in val_loader:
if use_cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, requires_grad=True), Variable(target)
output = net(data)
val = rightness(output, target)
vals.append(val)
val_r = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
############# 要在 GPU 训练,还需要转化这两个变量 ###################
val_r = torch.FloatTensor(val_r).cpu() if use_cuda else val_r
train_r = torch.FloatTensor(train_r).cpu() if use_cuda else train_r
#####################################################################
val_ratio = 1.0 * val_r[0].numpy() / val_r[1]
if val_ratio > best_r:
bast_r = val_ratio
best_model = copy.deepcopy(net)
print('训练周期:{} \tLoss:{:.6f} \t训练正确率:{:.2f}%,校验正确率:{:.2f}%'.format(
epoch, np.mean(train_losses),
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
record.append([np.mean(train_losses), 1. * train_r[0].data.numpy() / train_r[1], 1. * val_r[0].data.numpy() / val_r[1]])
t2 = time.time()
t2 - t1训练周期:0 Loss:0.364832 训练正确率:84.02%,校验正确率:94.12%
训练周期:1 Loss:0.087514 训练正确率:96.72%,校验正确率:95.42%
训练周期:2 Loss:0.071143 训练正确率:97.95%,校验正确率:93.46%
训练周期:3 Loss:0.071520 训练正确率:98.36%,校验正确率:95.42%
训练周期:4 Loss:0.079106 训练正确率:97.54%,校验正确率:94.77%
训练周期:5 Loss:0.092454 训练正确率:96.72%,校验正确率:94.12%
训练周期:6 Loss:0.089578 训练正确率:96.31%,校验正确率:94.77%
训练周期:7 Loss:0.104275 训练正确率:96.31%,校验正确率:95.42%
训练周期:8 Loss:0.062233 训练正确率:98.77%,校验正确率:95.42%
训练周期:9 Loss:0.077656 训练正确率:98.36%,校验正确率:93.46%
训练周期:10 Loss:0.078468 训练正确率:97.13%,校验正确率:94.77%
训练周期:11 Loss:0.099416 训练正确率:96.72%,校验正确率:94.77%
训练周期:12 Loss:0.058934 训练正确率:97.54%,校验正确率:95.42%
训练周期:13 Loss:0.124199 训练正确率:95.90%,校验正确率:94.77%
训练周期:14 Loss:0.064607 训练正确率:98.36%,校验正确率:93.46%
训练周期:15 Loss:0.084582 训练正确率:97.54%,校验正确率:94.77%
训练周期:16 Loss:0.110277 训练正确率:96.31%,校验正确率:95.42%
训练周期:17 Loss:0.062396 训练正确率:97.95%,校验正确率:94.77%
训练周期:18 Loss:0.078291 训练正确率:97.54%,校验正确率:94.77%
训练周期:19 Loss:0.044110 训练正确率:99.18%,校验正确率:94.77%绘制训练误差曲线,观察训练过程
# 绘制误差率曲线
x = [x[0] for x in record]
y = [1-x[1] for x in record]
z = [1-x[2] for x in record]
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练周期', size=15)
plt.ylabel('错误率', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC', size=18)
Text(0.5, 1.0, 'EzXxY PC')

将预训练的模型用于测试数据,并举例绘制出分类效果
visualize_model(net)
plt.ioff()
plt.show()






5. 系统化试验结果
观察上述三种模型分别训练十次的参数变化结果
# 原始模型训练十次各轮参数
origin[[[0.5832009, tensor(0.6762), tensor(0.6340)],
[0.58613235, tensor(0.7049), tensor(0.6667)],
[0.5807703, tensor(0.6598), tensor(0.6209)],
[0.5931609, tensor(0.6393), tensor(0.6993)],
[0.58817804, tensor(0.6598), tensor(0.6667)],
[0.582677, tensor(0.6803), tensor(0.6275)],
[0.5947113, tensor(0.6475), tensor(0.6732)],
[0.5746847, tensor(0.7049), tensor(0.6536)],
[0.5831697, tensor(0.6393), tensor(0.6797)],
[0.5898286, tensor(0.6639), tensor(0.6601)],
[0.5766389, tensor(0.6434), tensor(0.6863)],
[0.5746234, tensor(0.6516), tensor(0.6013)],
[0.58438414, tensor(0.6762), tensor(0.6601)],
[0.583, tensor(0.7049), tensor(0.6405)],
[0.5778625, tensor(0.6516), tensor(0.6536)],
[0.5687124, tensor(0.6885), tensor(0.6667)],
[0.56119645, tensor(0.6885), tensor(0.6275)],
[0.57675767, tensor(0.6557), tensor(0.6601)],
[0.57475954, tensor(0.6598), tensor(0.6667)],
[0.56502634, tensor(0.6967), tensor(0.6601)]],
[[0.57691306, tensor(0.6844), tensor(0.6471)],
[0.5750743, tensor(0.6598), tensor(0.6797)],
[0.5683227, tensor(0.7008), tensor(0.7190)],
[0.5815133, tensor(0.6721), tensor(0.6732)],
[0.5329753, tensor(0.7172), tensor(0.7059)],
[0.573538, tensor(0.6844), tensor(0.6340)],
[0.58498853, tensor(0.6762), tensor(0.6797)],
[0.5552865, tensor(0.7090), tensor(0.6797)],
[0.5717213, tensor(0.7172), tensor(0.6732)],
[0.5799343, tensor(0.6762), tensor(0.6928)],
[0.55402744, tensor(0.7049), tensor(0.6863)],
[0.5457029, tensor(0.7254), tensor(0.6667)],
[0.5559031, tensor(0.7172), tensor(0.6797)],
[0.5751221, tensor(0.6844), tensor(0.6275)],
[0.55986667, tensor(0.6885), tensor(0.6732)],
[0.5706693, tensor(0.7172), tensor(0.6667)],
[0.53643507, tensor(0.7090), tensor(0.6601)],
[0.5343603, tensor(0.7295), tensor(0.6732)],
[0.5423345, tensor(0.7582), tensor(0.6667)],
[0.5817876, tensor(0.7090), tensor(0.7320)]],
[[0.5284942, tensor(0.7377), tensor(0.7190)],
[0.5178238, tensor(0.7500), tensor(0.6928)],
[0.5585515, tensor(0.7295), tensor(0.6797)],
[0.53938836, tensor(0.7090), tensor(0.6536)],
[0.51378435, tensor(0.7131), tensor(0.6993)],
[0.5499272, tensor(0.7254), tensor(0.7255)],
[0.5540135, tensor(0.7377), tensor(0.6275)],
[0.52327543, tensor(0.7418), tensor(0.6601)],
[0.5253881, tensor(0.6967), tensor(0.6536)],
[0.55181015, tensor(0.7418), tensor(0.6928)],
[0.5299235, tensor(0.7090), tensor(0.6863)],
[0.51998854, tensor(0.7295), tensor(0.6797)],
[0.51413727, tensor(0.7172), tensor(0.6863)],
[0.5078945, tensor(0.7295), tensor(0.7190)],
[0.52321786, tensor(0.7090), tensor(0.7190)],
[0.53633976, tensor(0.7254), tensor(0.6993)],
[0.5041792, tensor(0.7213), tensor(0.6797)],
[0.48793045, tensor(0.7377), tensor(0.6928)],
[0.538765, tensor(0.7213), tensor(0.7190)],
[0.5318739, tensor(0.7131), tensor(0.6863)]],
[[0.5385022, tensor(0.6967), tensor(0.7320)],
[0.4961562, tensor(0.7172), tensor(0.6993)],
[0.51186997, tensor(0.7459), tensor(0.6797)],
[0.49389, tensor(0.7295), tensor(0.7190)],
[0.47413906, tensor(0.7828), tensor(0.7255)],
[0.49811953, tensor(0.7213), tensor(0.6797)],
[0.4801627, tensor(0.7541), tensor(0.6863)],
[0.50740075, tensor(0.7664), tensor(0.6863)],
[0.53165317, tensor(0.7418), tensor(0.7320)],
[0.48607627, tensor(0.7295), tensor(0.7451)],
[0.5180549, tensor(0.7377), tensor(0.7320)],
[0.51489305, tensor(0.7500), tensor(0.6471)],
[0.49785388, tensor(0.7213), tensor(0.7255)],
[0.51326096, tensor(0.7213), tensor(0.6536)],
[0.49314296, tensor(0.7623), tensor(0.6928)],
[0.50753534, tensor(0.7336), tensor(0.6928)],
[0.50173306, tensor(0.7377), tensor(0.7386)],
[0.48347965, tensor(0.7418), tensor(0.7059)],
[0.50262964, tensor(0.7172), tensor(0.6928)],
[0.49317172, tensor(0.7213), tensor(0.6993)]],
[[0.4981334, tensor(0.7213), tensor(0.7190)],
[0.4714278, tensor(0.7787), tensor(0.6928)],
[0.45258448, tensor(0.7623), tensor(0.7190)],
[0.47964987, tensor(0.7582), tensor(0.7059)],
[0.5044988, tensor(0.7172), tensor(0.7320)],
[0.48689988, tensor(0.7459), tensor(0.7320)],
[0.48961207, tensor(0.7459), tensor(0.7451)],
[0.49531567, tensor(0.7254), tensor(0.7386)],
[0.48238665, tensor(0.7828), tensor(0.7255)],
[0.50457263, tensor(0.7254), tensor(0.6797)],
[0.46702477, tensor(0.7377), tensor(0.6732)],
[0.48450956, tensor(0.7418), tensor(0.7647)],
[0.48803803, tensor(0.7500), tensor(0.7386)],
[0.46019745, tensor(0.7746), tensor(0.6863)],
[0.49421966, tensor(0.7705), tensor(0.7451)],
[0.49624738, tensor(0.7418), tensor(0.7582)],
[0.4951624, tensor(0.7377), tensor(0.7386)],
[0.48051298, tensor(0.7459), tensor(0.7059)],
[0.48772466, tensor(0.7746), tensor(0.7451)],
[0.4815896, tensor(0.7623), tensor(0.6797)]],
[[0.52978086, tensor(0.7090), tensor(0.7386)],
[0.48156303, tensor(0.7705), tensor(0.7516)],
[0.478834, tensor(0.7746), tensor(0.7190)],
[0.46914825, tensor(0.7623), tensor(0.6732)],
[0.46510687, tensor(0.7746), tensor(0.6993)],
[0.47693372, tensor(0.7664), tensor(0.6928)],
[0.45875373, tensor(0.7787), tensor(0.6928)],
[0.46909684, tensor(0.7828), tensor(0.6863)],
[0.45719334, tensor(0.7910), tensor(0.7255)],
[0.5163437, tensor(0.7623), tensor(0.6993)],
[0.4694729, tensor(0.7500), tensor(0.7124)],
[0.44292718, tensor(0.7787), tensor(0.7451)],
[0.4878115, tensor(0.7541), tensor(0.7386)],
[0.41451246, tensor(0.8115), tensor(0.7582)],
[0.47276706, tensor(0.7910), tensor(0.7124)],
[0.4707329, tensor(0.7623), tensor(0.7059)],
[0.43418422, tensor(0.7746), tensor(0.6732)],
[0.46557742, tensor(0.7582), tensor(0.6993)],
[0.4375037, tensor(0.7910), tensor(0.7386)],
[0.43540883, tensor(0.7664), tensor(0.7059)]],
[[0.46796253, tensor(0.7295), tensor(0.7255)],
[0.4586249, tensor(0.7746), tensor(0.6797)],
[0.43656522, tensor(0.8033), tensor(0.6797)],
[0.43911627, tensor(0.7828), tensor(0.6863)],
[0.43869463, tensor(0.7910), tensor(0.7059)],
[0.4565398, tensor(0.7582), tensor(0.6863)],
[0.4680813, tensor(0.7582), tensor(0.7255)],
[0.4725897, tensor(0.7459), tensor(0.7124)],
[0.42330003, tensor(0.8033), tensor(0.6667)],
[0.42605457, tensor(0.7992), tensor(0.7124)],
[0.4812617, tensor(0.7459), tensor(0.6797)],
[0.44479272, tensor(0.7705), tensor(0.7190)],
[0.43089914, tensor(0.7828), tensor(0.7124)],
[0.4306492, tensor(0.8033), tensor(0.7124)],
[0.4530706, tensor(0.7869), tensor(0.6993)],
[0.39562488, tensor(0.8074), tensor(0.7255)],
[0.43449336, tensor(0.8197), tensor(0.7059)],
[0.42365202, tensor(0.8156), tensor(0.7124)],
[0.41950536, tensor(0.8197), tensor(0.7386)],
[0.4209027, tensor(0.7910), tensor(0.6667)]],
[[0.45065725, tensor(0.7910), tensor(0.6732)],
[0.44119653, tensor(0.7910), tensor(0.6667)],
[0.44005856, tensor(0.8074), tensor(0.6928)],
[0.437199, tensor(0.8197), tensor(0.6928)],
[0.42365864, tensor(0.7787), tensor(0.7190)],
[0.4351052, tensor(0.7910), tensor(0.7386)],
[0.4401132, tensor(0.8074), tensor(0.7386)],
[0.41768885, tensor(0.8115), tensor(0.7255)],
[0.42133772, tensor(0.8197), tensor(0.6732)],
[0.4275099, tensor(0.8074), tensor(0.6797)],
[0.42612666, tensor(0.8033), tensor(0.6863)],
[0.4667402, tensor(0.7869), tensor(0.6797)],
[0.44013327, tensor(0.8074), tensor(0.6928)],
[0.50012594, tensor(0.7705), tensor(0.6797)],
[0.41024843, tensor(0.8156), tensor(0.7320)],
[0.4087193, tensor(0.8238), tensor(0.6667)],
[0.44831818, tensor(0.7582), tensor(0.7059)],
[0.3937297, tensor(0.8238), tensor(0.7190)],
[0.42578816, tensor(0.7910), tensor(0.7059)],
[0.43385836, tensor(0.8197), tensor(0.7386)]],
[[0.4415471, tensor(0.7828), tensor(0.6928)],
[0.39562255, tensor(0.8156), tensor(0.7124)],
[0.4396013, tensor(0.7992), tensor(0.6536)],
[0.43704504, tensor(0.7828), tensor(0.6797)],
[0.40805748, tensor(0.8115), tensor(0.6993)],
[0.39973944, tensor(0.8320), tensor(0.6928)],
[0.40987816, tensor(0.7992), tensor(0.6928)],
[0.43997926, tensor(0.8279), tensor(0.6732)],
[0.41752055, tensor(0.7869), tensor(0.6863)],
[0.39923206, tensor(0.8115), tensor(0.6667)],
[0.4125343, tensor(0.7705), tensor(0.6667)],
[0.40495712, tensor(0.8238), tensor(0.6993)],
[0.39947438, tensor(0.8115), tensor(0.6863)],
[0.4496099, tensor(0.8156), tensor(0.7059)],
[0.39878994, tensor(0.8361), tensor(0.7190)],
[0.39751905, tensor(0.8033), tensor(0.7059)],
[0.3907605, tensor(0.8156), tensor(0.6732)],
[0.41123092, tensor(0.7910), tensor(0.6928)],
[0.4100314, tensor(0.8361), tensor(0.7059)],
[0.43197957, tensor(0.7992), tensor(0.6863)]],
[[0.42862156, tensor(0.7951), tensor(0.6732)],
[0.44105473, tensor(0.7992), tensor(0.6863)],
[0.40321487, tensor(0.8156), tensor(0.6667)],
[0.41902572, tensor(0.8074), tensor(0.7190)],
[0.38641372, tensor(0.8074), tensor(0.7124)],
[0.363576, tensor(0.8320), tensor(0.7320)],
[0.47540382, tensor(0.7828), tensor(0.6797)],
[0.37392685, tensor(0.8279), tensor(0.7124)],
[0.415344, tensor(0.8033), tensor(0.6928)],
[0.37696728, tensor(0.8156), tensor(0.6928)],
[0.4101135, tensor(0.8361), tensor(0.6863)],
[0.39324197, tensor(0.8197), tensor(0.6993)],
[0.42219764, tensor(0.8033), tensor(0.7255)],
[0.38043, tensor(0.8402), tensor(0.7124)],
[0.39631522, tensor(0.8238), tensor(0.7124)],
[0.370933, tensor(0.8238), tensor(0.6863)],
[0.40298223, tensor(0.7951), tensor(0.6928)],
[0.38444206, tensor(0.8074), tensor(0.7124)],
[0.39431056, tensor(0.8238), tensor(0.7059)],
[0.3952283, tensor(0.8361), tensor(0.6732)]]]# 预训练的 ResNet18 模型训练十次各轮参数
pre_training[[[0.6859839, tensor(0.5369), tensor(0.8366)],
[0.39821917, tensor(0.8033), tensor(0.8824)],
[0.23271726, tensor(0.9262), tensor(0.9412)],
[0.17509396, tensor(0.9385), tensor(0.9477)],
[0.19228166, tensor(0.9385), tensor(0.9281)],
[0.13800085, tensor(0.9508), tensor(0.8497)],
[0.1689934, tensor(0.9344), tensor(0.8889)],
[0.13816139, tensor(0.9467), tensor(0.9085)],
[0.16033036, tensor(0.9303), tensor(0.9412)],
[0.10007073, tensor(0.9631), tensor(0.9477)],
[0.09956869, tensor(0.9590), tensor(0.8889)],
[0.076089025, tensor(0.9672), tensor(0.9542)],
[0.06169852, tensor(0.9795), tensor(0.9412)],
[0.05034053, tensor(0.9795), tensor(0.9477)],
[0.107640296, tensor(0.9508), tensor(0.9281)],
[0.047273584, tensor(0.9877), tensor(0.9412)],
[0.048108384, tensor(0.9836), tensor(0.9477)],
[0.054773815, tensor(0.9795), tensor(0.9085)],
[0.10938168, tensor(0.9754), tensor(0.9412)],
[0.05270767, tensor(0.9836), tensor(0.9281)]],
[[0.39024603, tensor(0.8115), tensor(0.9412)],
[0.097178265, tensor(0.9836), tensor(0.9673)],
[0.056254786, tensor(0.9918), tensor(0.9346)],
[0.050816808, tensor(0.9877), tensor(0.9281)],
[0.08329505, tensor(0.9795), tensor(0.9216)],
[0.09120789, tensor(0.9631), tensor(0.8758)],
[0.08045757, tensor(0.9590), tensor(0.9346)],
[0.05869491, tensor(0.9754), tensor(0.9477)],
[0.058591958, tensor(0.9754), tensor(0.9150)],
[0.09907335, tensor(0.9713), tensor(0.9412)],
[0.082146615, tensor(0.9672), tensor(0.9020)],
[0.047808517, tensor(0.9836), tensor(0.9608)],
[0.06675532, tensor(0.9836), tensor(0.9216)],
[0.11492418, tensor(0.9508), tensor(0.8758)],
[0.09464877, tensor(0.9508), tensor(0.9216)],
[0.067065015, tensor(0.9713), tensor(0.9346)],
[0.04387285, tensor(0.9918), tensor(0.9412)],
[0.04273611, tensor(0.9918), tensor(0.9477)],
[0.02422124, tensor(0.9918), tensor(0.9542)],
[0.032989327, tensor(0.9836), tensor(0.9281)]],
[[0.31451347, tensor(0.8484), tensor(0.9542)],
[0.0835316, tensor(0.9672), tensor(0.9542)],
[0.05385894, tensor(0.9836), tensor(0.9608)],
[0.050001208, tensor(0.9877), tensor(0.9412)],
[0.05739398, tensor(0.9795), tensor(0.9542)],
[0.07507658, tensor(0.9795), tensor(0.9412)],
[0.030161984, tensor(0.9877), tensor(0.9542)],
[0.040794797, tensor(0.9754), tensor(0.9542)],
[0.06899194, tensor(0.9795), tensor(0.9346)],
[0.036544684, tensor(0.9877), tensor(0.9477)],
[0.034788232, tensor(0.9918), tensor(0.9216)],
[0.030344283, tensor(0.9877), tensor(0.9281)],
[0.11047168, tensor(0.9590), tensor(0.9477)],
[0.052896205, tensor(0.9795), tensor(0.9477)],
[0.043976206, tensor(0.9918), tensor(0.9477)],
[0.03840863, tensor(0.9877), tensor(0.9281)],
[0.038057998, tensor(0.9836), tensor(0.9216)],
[0.0492152, tensor(0.9877), tensor(0.9150)],
[0.06609126, tensor(0.9631), tensor(0.9412)],
[0.04347869, tensor(0.9836), tensor(0.9542)]],
[[0.3452085, tensor(0.8320), tensor(0.9542)],
[0.0608055, tensor(0.9836), tensor(0.9608)],
[0.03640233, tensor(0.9836), tensor(0.9281)],
[0.03654557, tensor(0.9836), tensor(0.9542)],
[0.02774512, tensor(0.9959), tensor(0.9477)],
[0.023690376, tensor(0.9959), tensor(0.9412)],
[0.021986442, tensor(0.9877), tensor(0.9542)],
[0.025722044, tensor(0.9959), tensor(0.9542)],
[0.033192985, tensor(0.9836), tensor(0.9412)],
[0.02883289, tensor(0.9918), tensor(0.9608)],
[0.025635866, tensor(0.9877), tensor(0.9216)],
[0.027215147, tensor(0.9918), tensor(0.9542)],
[0.044736795, tensor(0.9877), tensor(0.9150)],
[0.013105465, tensor(1.0000), tensor(0.9542)],
[0.051554386, tensor(0.9754), tensor(0.9542)],
[0.044996165, tensor(0.9918), tensor(0.9281)],
[0.048149616, tensor(0.9836), tensor(0.9542)],
[0.034887817, tensor(0.9836), tensor(0.9412)],
[0.053095367, tensor(0.9754), tensor(0.9150)],
[0.09239031, tensor(0.9672), tensor(0.9412)]],
[[0.34182802, tensor(0.8648), tensor(0.9542)],
[0.06834241, tensor(0.9795), tensor(0.9608)],
[0.020613024, tensor(1.0000), tensor(0.9542)],
[0.017558625, tensor(0.9918), tensor(0.9477)],
[0.03165181, tensor(0.9877), tensor(0.9542)],
[0.035169993, tensor(0.9836), tensor(0.9477)],
[0.03625763, tensor(0.9877), tensor(0.9608)],
[0.017008582, tensor(0.9959), tensor(0.9608)],
[0.022309603, tensor(0.9918), tensor(0.9542)],
[0.024073726, tensor(0.9918), tensor(0.9542)],
[0.032889754, tensor(0.9877), tensor(0.9542)],
[0.014791567, tensor(0.9959), tensor(0.9542)],
[0.019422373, tensor(0.9918), tensor(0.9477)],
[0.04127106, tensor(0.9836), tensor(0.9412)],
[0.035787817, tensor(0.9877), tensor(0.9346)],
[0.018600821, tensor(0.9959), tensor(0.9542)],
[0.020849444, tensor(0.9877), tensor(0.9346)],
[0.015509855, tensor(0.9918), tensor(0.9412)],
[0.015550316, tensor(1.0000), tensor(0.9281)],
[0.06613971, tensor(0.9795), tensor(0.9216)]],
[[0.30834463, tensor(0.8730), tensor(0.9608)],
[0.02975232, tensor(0.9959), tensor(0.9346)],
[0.018849667, tensor(0.9959), tensor(0.9542)],
[0.021100666, tensor(0.9959), tensor(0.9542)],
[0.027836986, tensor(0.9877), tensor(0.9542)],
[0.01445023, tensor(0.9959), tensor(0.9542)],
[0.07511834, tensor(0.9713), tensor(0.9216)],
[0.03591576, tensor(0.9754), tensor(0.9608)],
[0.035023477, tensor(0.9836), tensor(0.9542)],
[0.03261094, tensor(0.9877), tensor(0.9412)],
[0.022745835, tensor(0.9918), tensor(0.9608)],
[0.036931172, tensor(0.9795), tensor(0.9542)],
[0.052205354, tensor(0.9795), tensor(0.9477)],
[0.024772722, tensor(0.9877), tensor(0.9542)],
[0.0165482, tensor(0.9918), tensor(0.9542)],
[0.0150261, tensor(0.9918), tensor(0.9281)],
[0.04087264, tensor(0.9836), tensor(0.9346)],
[0.015898969, tensor(1.0000), tensor(0.9412)],
[0.0073492336, tensor(1.0000), tensor(0.9412)],
[0.020362096, tensor(0.9918), tensor(0.9150)]],
[[0.295248, tensor(0.8934), tensor(0.9608)],
[0.03516052, tensor(0.9918), tensor(0.9477)],
[0.028089618, tensor(0.9959), tensor(0.9412)],
[0.0320893, tensor(0.9877), tensor(0.8889)],
[0.037944555, tensor(0.9918), tensor(0.9346)],
[0.040959153, tensor(0.9795), tensor(0.9020)],
[0.027334094, tensor(0.9918), tensor(0.9085)],
[0.024610046, tensor(0.9877), tensor(0.9477)],
[0.023041205, tensor(0.9918), tensor(0.9085)],
[0.020419877, tensor(0.9918), tensor(0.9281)],
[0.038649127, tensor(0.9877), tensor(0.9412)],
[0.030577213, tensor(0.9918), tensor(0.9281)],
[0.017090835, tensor(0.9959), tensor(0.9477)],
[0.035755947, tensor(0.9795), tensor(0.9150)],
[0.035726767, tensor(0.9836), tensor(0.9020)],
[0.02957103, tensor(0.9836), tensor(0.8889)],
[0.056084964, tensor(0.9877), tensor(0.9020)],
[0.046774488, tensor(0.9836), tensor(0.9281)],
[0.021828635, tensor(0.9918), tensor(0.9542)],
[0.008027037, tensor(1.0000), tensor(0.9542)]],
[[0.29286045, tensor(0.8811), tensor(0.9477)],
[0.06338362, tensor(0.9877), tensor(0.9477)],
[0.023732422, tensor(0.9959), tensor(0.9281)],
[0.018041344, tensor(1.0000), tensor(0.9412)],
[0.01722437, tensor(0.9959), tensor(0.9216)],
[0.02298397, tensor(0.9959), tensor(0.9412)],
[0.010304216, tensor(1.0000), tensor(0.9477)],
[0.02617435, tensor(0.9877), tensor(0.9216)],
[0.032066885, tensor(0.9918), tensor(0.9412)],
[0.046322428, tensor(0.9836), tensor(0.9281)],
[0.017761284, tensor(0.9959), tensor(0.9477)],
[0.035205197, tensor(0.9877), tensor(0.9542)],
[0.040084597, tensor(0.9754), tensor(0.9542)],
[0.029620847, tensor(0.9877), tensor(0.9346)],
[0.012956627, tensor(1.0000), tensor(0.9542)],
[0.051181242, tensor(0.9754), tensor(0.9085)],
[0.021205677, tensor(0.9918), tensor(0.9412)],
[0.024373483, tensor(0.9918), tensor(0.9412)],
[0.012174638, tensor(0.9959), tensor(0.9412)],
[0.014131403, tensor(0.9959), tensor(0.9412)]],
[[0.19659664, tensor(0.9262), tensor(0.9346)],
[0.018670967, tensor(1.0000), tensor(0.9477)],
[0.027702333, tensor(0.9877), tensor(0.9477)],
[0.02107815, tensor(1.0000), tensor(0.9542)],
[0.020263564, tensor(0.9918), tensor(0.9346)],
[0.02579412, tensor(0.9836), tensor(0.9281)],
[0.04115618, tensor(0.9754), tensor(0.9477)],
[0.020745203, tensor(0.9918), tensor(0.9150)],
[0.022397533, tensor(0.9877), tensor(0.9150)],
[0.056386363, tensor(0.9754), tensor(0.9542)],
[0.020762904, tensor(0.9959), tensor(0.9412)],
[0.07273981, tensor(0.9795), tensor(0.9346)],
[0.03212775, tensor(0.9877), tensor(0.9281)],
[0.04659757, tensor(0.9795), tensor(0.9608)],
[0.01481438, tensor(0.9959), tensor(0.9608)],
[0.013241989, tensor(1.0000), tensor(0.9608)],
[0.012584229, tensor(0.9918), tensor(0.9477)],
[0.020857535, tensor(0.9877), tensor(0.9346)],
[0.057330832, tensor(0.9713), tensor(0.9412)],
[0.020944348, tensor(0.9959), tensor(0.9542)]],
[[0.16262059, tensor(0.9426), tensor(0.9346)],
[0.02568111, tensor(0.9959), tensor(0.9412)],
[0.0172276, tensor(1.0000), tensor(0.9150)],
[0.01982439, tensor(0.9959), tensor(0.9542)],
[0.03171318, tensor(0.9877), tensor(0.9412)],
[0.010059243, tensor(0.9959), tensor(0.9477)],
[0.02762681, tensor(0.9877), tensor(0.9346)],
[0.033128534, tensor(0.9877), tensor(0.9281)],
[0.018703278, tensor(0.9918), tensor(0.9477)],
[0.031238155, tensor(0.9918), tensor(0.9346)],
[0.056238577, tensor(0.9836), tensor(0.9542)],
[0.04674203, tensor(0.9795), tensor(0.9542)],
[0.017943287, tensor(1.0000), tensor(0.9542)],
[0.019397229, tensor(0.9918), tensor(0.9477)],
[0.032023888, tensor(0.9877), tensor(0.9477)],
[0.027226372, tensor(0.9918), tensor(0.9608)],
[0.01676273, tensor(0.9918), tensor(0.9542)],
[0.013900694, tensor(1.0000), tensor(0.9477)],
[0.012057008, tensor(1.0000), tensor(0.9346)],
[0.053891387, tensor(0.9754), tensor(0.8366)]]]# 固定值的 ResNet18 模型训练十次各轮参数
fixed_value[[[0.69027525, tensor(0.5246), tensor(0.7516)],
[0.52930194, tensor(0.7705), tensor(0.8497)],
[0.39292663, tensor(0.8811), tensor(0.9281)],
[0.31931657, tensor(0.8934), tensor(0.9346)],
[0.30318305, tensor(0.8975), tensor(0.9477)],
[0.25243703, tensor(0.9385), tensor(0.9412)],
[0.23880868, tensor(0.9344), tensor(0.9346)],
[0.21638225, tensor(0.9344), tensor(0.9412)],
[0.21103476, tensor(0.9508), tensor(0.9412)],
[0.22414075, tensor(0.9303), tensor(0.9477)],
[0.19291611, tensor(0.9426), tensor(0.9412)],
[0.18841156, tensor(0.9303), tensor(0.9542)],
[0.18149953, tensor(0.9467), tensor(0.9542)],
[0.1894776, tensor(0.9467), tensor(0.9542)],
[0.17891732, tensor(0.9508), tensor(0.9412)],
[0.20496136, tensor(0.9344), tensor(0.9542)],
[0.17512177, tensor(0.9385), tensor(0.9542)],
[0.16695459, tensor(0.9467), tensor(0.9542)],
[0.14652927, tensor(0.9590), tensor(0.9608)],
[0.14578092, tensor(0.9631), tensor(0.9542)]],
[[0.3522909, tensor(0.8525), tensor(0.9412)],
[0.14442246, tensor(0.9467), tensor(0.9346)],
[0.15930294, tensor(0.9467), tensor(0.9412)],
[0.119438834, tensor(0.9795), tensor(0.9412)],
[0.1383972, tensor(0.9508), tensor(0.9412)],
[0.16867034, tensor(0.9221), tensor(0.9346)],
[0.11949797, tensor(0.9754), tensor(0.9412)],
[0.15970553, tensor(0.9344), tensor(0.9412)],
[0.13591842, tensor(0.9508), tensor(0.9412)],
[0.12979601, tensor(0.9672), tensor(0.9346)],
[0.130426, tensor(0.9672), tensor(0.9346)],
[0.114111476, tensor(0.9590), tensor(0.9412)],
[0.15398705, tensor(0.9303), tensor(0.9412)],
[0.13585888, tensor(0.9508), tensor(0.9412)],
[0.11402238, tensor(0.9672), tensor(0.9412)],
[0.14903063, tensor(0.9344), tensor(0.9412)],
[0.12502044, tensor(0.9672), tensor(0.9412)],
[0.10829593, tensor(0.9549), tensor(0.9412)],
[0.14506817, tensor(0.9385), tensor(0.9412)],
[0.116747856, tensor(0.9672), tensor(0.9412)]],
[[0.38313875, tensor(0.8279), tensor(0.9477)],
[0.13000998, tensor(0.9590), tensor(0.9542)],
[0.118908376, tensor(0.9631), tensor(0.9542)],
[0.12330982, tensor(0.9631), tensor(0.9542)],
[0.1271113, tensor(0.9590), tensor(0.9542)],
[0.133874, tensor(0.9385), tensor(0.9542)],
[0.11769894, tensor(0.9713), tensor(0.9477)],
[0.1122008, tensor(0.9672), tensor(0.9542)],
[0.13901417, tensor(0.9426), tensor(0.9542)],
[0.13406445, tensor(0.9508), tensor(0.9542)],
[0.11168926, tensor(0.9549), tensor(0.9542)],
[0.1093618, tensor(0.9590), tensor(0.9542)],
[0.12570718, tensor(0.9672), tensor(0.9542)],
[0.13949794, tensor(0.9426), tensor(0.9542)],
[0.0937551, tensor(0.9672), tensor(0.9477)],
[0.100697555, tensor(0.9754), tensor(0.9542)],
[0.09912491, tensor(0.9754), tensor(0.9542)],
[0.1095627, tensor(0.9631), tensor(0.9542)],
[0.11730321, tensor(0.9754), tensor(0.9542)],
[0.13544405, tensor(0.9590), tensor(0.9477)]],
[[0.31790134, tensor(0.8607), tensor(0.9542)],
[0.11296136, tensor(0.9672), tensor(0.9477)],
[0.093263015, tensor(0.9754), tensor(0.9477)],
[0.113042094, tensor(0.9426), tensor(0.9477)],
[0.1593707, tensor(0.9385), tensor(0.9412)],
[0.098183244, tensor(0.9672), tensor(0.9412)],
[0.11959996, tensor(0.9508), tensor(0.9412)],
[0.1196224, tensor(0.9631), tensor(0.9542)],
[0.105494134, tensor(0.9713), tensor(0.9412)],
[0.14358425, tensor(0.9508), tensor(0.9412)],
[0.11910246, tensor(0.9426), tensor(0.9477)],
[0.13063218, tensor(0.9590), tensor(0.9477)],
[0.11028271, tensor(0.9713), tensor(0.9412)],
[0.1077459, tensor(0.9672), tensor(0.9412)],
[0.12720907, tensor(0.9549), tensor(0.9542)],
[0.09756297, tensor(0.9713), tensor(0.9477)],
[0.11565501, tensor(0.9590), tensor(0.9477)],
[0.09422805, tensor(0.9713), tensor(0.9412)],
[0.10094272, tensor(0.9754), tensor(0.9412)],
[0.09251677, tensor(0.9631), tensor(0.9412)]],
[[0.3604203, tensor(0.8402), tensor(0.9542)],
[0.088693276, tensor(0.9795), tensor(0.9542)],
[0.08803402, tensor(0.9754), tensor(0.9542)],
[0.08312686, tensor(0.9795), tensor(0.9412)],
[0.121706255, tensor(0.9672), tensor(0.9477)],
[0.12346601, tensor(0.9590), tensor(0.9477)],
[0.085761435, tensor(0.9795), tensor(0.9477)],
[0.106196694, tensor(0.9590), tensor(0.9477)],
[0.08789483, tensor(0.9877), tensor(0.9412)],
[0.07704165, tensor(0.9754), tensor(0.9477)],
[0.07291679, tensor(0.9918), tensor(0.9542)],
[0.10107622, tensor(0.9713), tensor(0.9477)],
[0.07430885, tensor(0.9836), tensor(0.9477)],
[0.10931267, tensor(0.9795), tensor(0.9477)],
[0.092028625, tensor(0.9836), tensor(0.9477)],
[0.08452151, tensor(0.9795), tensor(0.9477)],
[0.12777856, tensor(0.9672), tensor(0.9477)],
[0.09012622, tensor(0.9672), tensor(0.9477)],
[0.10154129, tensor(0.9590), tensor(0.9477)],
[0.100499354, tensor(0.9713), tensor(0.9477)]],
[[0.3800231, tensor(0.8279), tensor(0.9477)],
[0.095545545, tensor(0.9713), tensor(0.9477)],
[0.08874494, tensor(0.9672), tensor(0.9477)],
[0.078482985, tensor(0.9836), tensor(0.9412)],
[0.107627265, tensor(0.9590), tensor(0.9477)],
[0.107246935, tensor(0.9713), tensor(0.9412)],
[0.12401097, tensor(0.9508), tensor(0.9477)],
[0.09427943, tensor(0.9795), tensor(0.9412)],
[0.08737071, tensor(0.9754), tensor(0.9477)],
[0.09113083, tensor(0.9754), tensor(0.9412)],
[0.11498574, tensor(0.9590), tensor(0.9477)],
[0.08872403, tensor(0.9672), tensor(0.9412)],
[0.08411044, tensor(0.9672), tensor(0.9412)],
[0.09881529, tensor(0.9590), tensor(0.9412)],
[0.09698549, tensor(0.9631), tensor(0.9412)],
[0.122847065, tensor(0.9508), tensor(0.9412)],
[0.06701706, tensor(0.9795), tensor(0.9412)],
[0.09824372, tensor(0.9713), tensor(0.9412)],
[0.08552852, tensor(0.9672), tensor(0.9412)],
[0.10837344, tensor(0.9549), tensor(0.9412)]],
[[0.323946, tensor(0.8607), tensor(0.9477)],
[0.097994834, tensor(0.9590), tensor(0.9412)],
[0.098252065, tensor(0.9631), tensor(0.9477)],
[0.10002246, tensor(0.9508), tensor(0.9477)],
[0.07298785, tensor(0.9795), tensor(0.9281)],
[0.07972227, tensor(0.9713), tensor(0.9412)],
[0.07936333, tensor(0.9877), tensor(0.9281)],
[0.13627778, tensor(0.9590), tensor(0.9477)],
[0.09981127, tensor(0.9672), tensor(0.9477)],
[0.07010228, tensor(0.9836), tensor(0.9412)],
[0.076169, tensor(0.9877), tensor(0.9412)],
[0.11001262, tensor(0.9549), tensor(0.9281)],
[0.078631654, tensor(0.9754), tensor(0.9412)],
[0.08940843, tensor(0.9713), tensor(0.9477)],
[0.11617876, tensor(0.9590), tensor(0.9216)],
[0.10129914, tensor(0.9631), tensor(0.9216)],
[0.0894757, tensor(0.9754), tensor(0.9477)],
[0.088809274, tensor(0.9672), tensor(0.9346)],
[0.065393016, tensor(0.9795), tensor(0.9477)],
[0.090635516, tensor(0.9672), tensor(0.9477)]],
[[0.38110963, tensor(0.8484), tensor(0.9477)],
[0.0939671, tensor(0.9754), tensor(0.9542)],
[0.08356253, tensor(0.9713), tensor(0.9477)],
[0.09349469, tensor(0.9795), tensor(0.9542)],
[0.09638216, tensor(0.9590), tensor(0.9477)],
[0.086979955, tensor(0.9795), tensor(0.9542)],
[0.05557073, tensor(0.9877), tensor(0.9542)],
[0.072343975, tensor(0.9754), tensor(0.9542)],
[0.07126898, tensor(0.9836), tensor(0.9477)],
[0.08661291, tensor(0.9631), tensor(0.9542)],
[0.061895046, tensor(0.9836), tensor(0.9542)],
[0.1122564, tensor(0.9467), tensor(0.9477)],
[0.06695068, tensor(0.9754), tensor(0.9542)],
[0.076601215, tensor(0.9795), tensor(0.9477)],
[0.08582625, tensor(0.9754), tensor(0.9477)],
[0.08818093, tensor(0.9754), tensor(0.9542)],
[0.09410669, tensor(0.9590), tensor(0.9477)],
[0.060765926, tensor(0.9836), tensor(0.9542)],
[0.08170537, tensor(0.9754), tensor(0.9412)],
[0.088581435, tensor(0.9631), tensor(0.9477)]],
[[0.4759104, tensor(0.7869), tensor(0.9412)],
[0.10443838, tensor(0.9631), tensor(0.9412)],
[0.078134626, tensor(0.9795), tensor(0.9477)],
[0.08787043, tensor(0.9754), tensor(0.9412)],
[0.054374192, tensor(0.9836), tensor(0.9477)],
[0.08406415, tensor(0.9713), tensor(0.9477)],
[0.07475983, tensor(0.9754), tensor(0.9412)],
[0.07475102, tensor(0.9754), tensor(0.9412)],
[0.0836129, tensor(0.9877), tensor(0.9412)],
[0.06749928, tensor(0.9713), tensor(0.9412)],
[0.08926262, tensor(0.9795), tensor(0.9542)],
[0.09002572, tensor(0.9631), tensor(0.9412)],
[0.085841164, tensor(0.9795), tensor(0.9412)],
[0.07272764, tensor(0.9836), tensor(0.9542)],
[0.055545047, tensor(0.9795), tensor(0.9412)],
[0.06919439, tensor(0.9713), tensor(0.9542)],
[0.10415088, tensor(0.9672), tensor(0.9412)],
[0.0696273, tensor(0.9754), tensor(0.9477)],
[0.10988377, tensor(0.9631), tensor(0.9412)],
[0.105634436, tensor(0.9631), tensor(0.9477)]],
[[0.36483213, tensor(0.8402), tensor(0.9412)],
[0.08751389, tensor(0.9672), tensor(0.9542)],
[0.07114252, tensor(0.9795), tensor(0.9346)],
[0.07152027, tensor(0.9836), tensor(0.9542)],
[0.079106346, tensor(0.9754), tensor(0.9477)],
[0.09245436, tensor(0.9672), tensor(0.9412)],
[0.0895782, tensor(0.9631), tensor(0.9477)],
[0.104275055, tensor(0.9631), tensor(0.9542)],
[0.062233288, tensor(0.9877), tensor(0.9542)],
[0.07765594, tensor(0.9836), tensor(0.9346)],
[0.07846775, tensor(0.9713), tensor(0.9477)],
[0.0994159, tensor(0.9672), tensor(0.9477)],
[0.058934018, tensor(0.9754), tensor(0.9542)],
[0.12419942, tensor(0.9590), tensor(0.9477)],
[0.064607374, tensor(0.9836), tensor(0.9346)],
[0.084581815, tensor(0.9754), tensor(0.9477)],
[0.11027667, tensor(0.9631), tensor(0.9542)],
[0.062396437, tensor(0.9795), tensor(0.9477)],
[0.07829092, tensor(0.9754), tensor(0.9477)],
[0.04410958, tensor(0.9918), tensor(0.9477)]]]原始模型各轮均值可视化显示结果
# 对每个模型的 10 次循环分别求均值
train_rights1 = []
val_rights1 = []
for n in range(10):
train_r = 0
for i in range(10):
train_r += origin[i][n][1]
train_r = train_r / 10
train_rights1.append(train_r)
val_r = 0
for i in range(10):
val_r += origin[i][n][2]
val_r = val_r / 10
val_rights1.append(val_r)
# 绘制误差率曲线
x = range(0, 20)
y = torch.ones(10,1) - np.array(train_rights1).reshape(10,1)
z = torch.ones(10,1) - np.array(val_rights1).reshape(10,1)
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练次数', size=15)
plt.ylabel('错误率均值', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC——原始模型', size=18)
Text(0.5, 1.0, 'EzXxY PC——原始模型')

预训练模型
# 对每个模型的 10 次循环分别求均值
train_rights2 = []
val_rights2 = []
for n in range(10):
train_r = 0
for i in range(10):
train_r += pre_training[i][n][1]
train_r = train_r / 10
train_rights2.append(train_r)
val_r = 0
for i in range(10):
val_r += pre_training[i][n][2]
val_r = val_r / 10
val_rights2.append(val_r)
# 绘制误差率曲线
x = range(0, 20)
y = torch.ones(10,1) - np.array(train_rights2).reshape(10,1)
z = torch.ones(10,1) - np.array(val_rights2).reshape(10,1)
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练次数', size=15)
plt.ylabel('错误率均值', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC——预训练模型', size=18)
Text(0.5, 1.0, 'EzXxY PC——预训练模型')

固定值模型
# 对每个模型的 10 次循环分别求均值
train_rights3 = []
val_rights3 = []
for n in range(10):
train_r = 0
for i in range(10):
train_r += fixed_value[i][n][1]
train_r = train_r / 10
train_rights3.append(train_r)
val_r = 0
for i in range(10):
val_r += fixed_value[i][n][2]
val_r = val_r / 10
val_rights3.append(val_r)
# 绘制误差率曲线
x = range(0, 20)
y = torch.ones(10,1) - np.array(train_rights3).reshape(10,1)
z = torch.ones(10,1) - np.array(val_rights3).reshape(10,1)
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1, = plt.plot(y)
error2, = plt.plot(z)
plt.xlabel('训练次数', size=15)
plt.ylabel('错误率均值', size=15)
str1 = '训练错误率' #图例信息
str2 = '校验错误率' #图例信息
plt.legend([error1, error2], [str1, str2])#绘制图例
plt.title('EzXxY PC——固定值模型', size=18)
Text(0.5, 1.0, 'EzXxY PC——固定值模型')

将上述各模型结果画到一起进行比较
# 绘制误差率曲线
x = range(0, 20)
y1 = torch.ones(10,1) - np.array(train_rights1).reshape(10,1)
z1 = torch.ones(10,1) - np.array(val_rights1).reshape(10,1)
y2 = torch.ones(10,1) - np.array(train_rights2).reshape(10,1)
z2 = torch.ones(10,1) - np.array(val_rights2).reshape(10,1)
y3 = torch.ones(10,1) - np.array(train_rights3).reshape(10,1)
z3 = torch.ones(10,1) - np.array(val_rights3).reshape(10,1)
# 显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.plot(x)
plt.figure(figsize=(10, 7))
error1_1, = plt.plot(y1)
error2_1, = plt.plot(z1)
error1_2, = plt.plot(y2)
error2_2, = plt.plot(z2)
error1_3, = plt.plot(y3)
error2_3, = plt.plot(z3)
plt.xlabel('训练次数', size=15)
plt.ylabel('错误率均值', size=15)
str1 = '原始模型训练错误率' #图例信息
str2 = '原始模型校验错误率' #图例信息
str3 = '预训练模型训练错误率' #图例信息
str4 = '预训练模型校验错误率' #图例信息
str5 = '固定值模型训练错误率' #图例信息
str6 = '固定值模型校验错误率' #图例信息
plt.legend([error1_1, error2_1, error1_2, error2_2, error1_3, error2_3], [str1, str2, str3, str4, str5, str6])#绘制图例
plt.title('EzXxY PC——三种模型比较', size=18)
Text(0.5, 1.0, 'EzXxY PC——三种模型比较')

从图中可以看出,原始模型毫无疑问地表现最差,错误率大约在 28% ,其实人家也没有在瞎猜,只是猜得正确率差不多能上 70% ;在此次任务中,预训练模式和固定值模式训练出来的迁移模型差别并不大,预训练模式下的训练错误率整体比固定值模式的训练错误率要低约4%,而校验错误率整体来看又高了约1%,可见预训练模式比固定值模式增加了一定的过拟合风险,但也相差不大。总体而言,还是预训练模式下的迁移学习模型更胜一筹。
6. 小结
val_dataset = datasets.ImageFolder(os.path.join(data_dir, 'val'))——加载校验集;
加载本地数据时可以自定义数据增强操作
transforms.Compose([···])可以自定义网络结构实现自己的小目标。
迁移学习的方式可以使用少量数据完成高精度任务,迁移学习包括预训练模式和固定值模式2种;
预训练模式一般效果更好,但是训练时间比固定值模式长;
固定值模式可以保留大型网络的参数,只需学习自我定制模块的参数即可。

