在深度学习的 计算机视觉(CV) 方向游玩之后,再让我们回过头来看看 自然语言处理(NLP) 方向的简单模型吧!~
1. 期望目标
① 剖析循环神经网络(RNN)模型 与 长短期记忆网络(LSTM)模型的联系与区别
② 学会使用 RNN 模型生成 $ 0^n1^n $ 序列的方法
③ 学会使用 LSTM 模型生成 $ 0^n1^n $ 序列的方法
2. 上下文无关文法与上下文无关文法序列
所谓上下文无关文法(Context-freegrammar),简单来说,就是可以被一组替代规则所生成,而与本身所处的上下文(前后出现的字符)无关的语法。从数字序列来看,对于只含有 0 和 1 并连续地出现,序列长度并不相等,但在每条序列中 0 和 1 的个数是相等的序列叫做上下文无关文法序列。
3. RNN 与 LSTM 的联系与区别
LSTM 模型是 RNN 模型的升级版,它在 RNN 模型的每一个隐藏层都加入了参数可训练的存储器 Cell,使得记忆力不太好的 RNN 升级为可以进行长短时记忆的 LSTM 。
RNN 模型的整体架构如下所示:
其中输入层(Input Layer)应当提前转化为独热(one-hot)编码,或者在定义网络架构时,加入嵌入(Embedding)层;隐含层(Hidden Layer)中的神经元处于全连接状态。
RNN 模型在时间上展开为如下形式:
$$ h_t = \sigma(W_{xh}X_t + W_{hh}h_{t-1}) $$
$$ Y_t = \sigma(W_{hY}h_t) $$
RNN 模型与 LSTM 模型在隐含层的运算中的差异如下图所示:
从上图可以看出,RNN 模型在一个隐含层单元中只是做了1步简单的双曲正切计算,而 LSTM 模型将1个隐含层的运算过程变为了6步。这就是 LSTM 相较于 RNN 升级的地方,它在每一个隐含层神经元中加入了这种可以存储8个参数的结构,简称为1个“Cell”。这样在训练网络时,每一个隐含层神经元就可以多保存8个参数,使得升级后的 RNN 能够拥有更强的记忆能力。
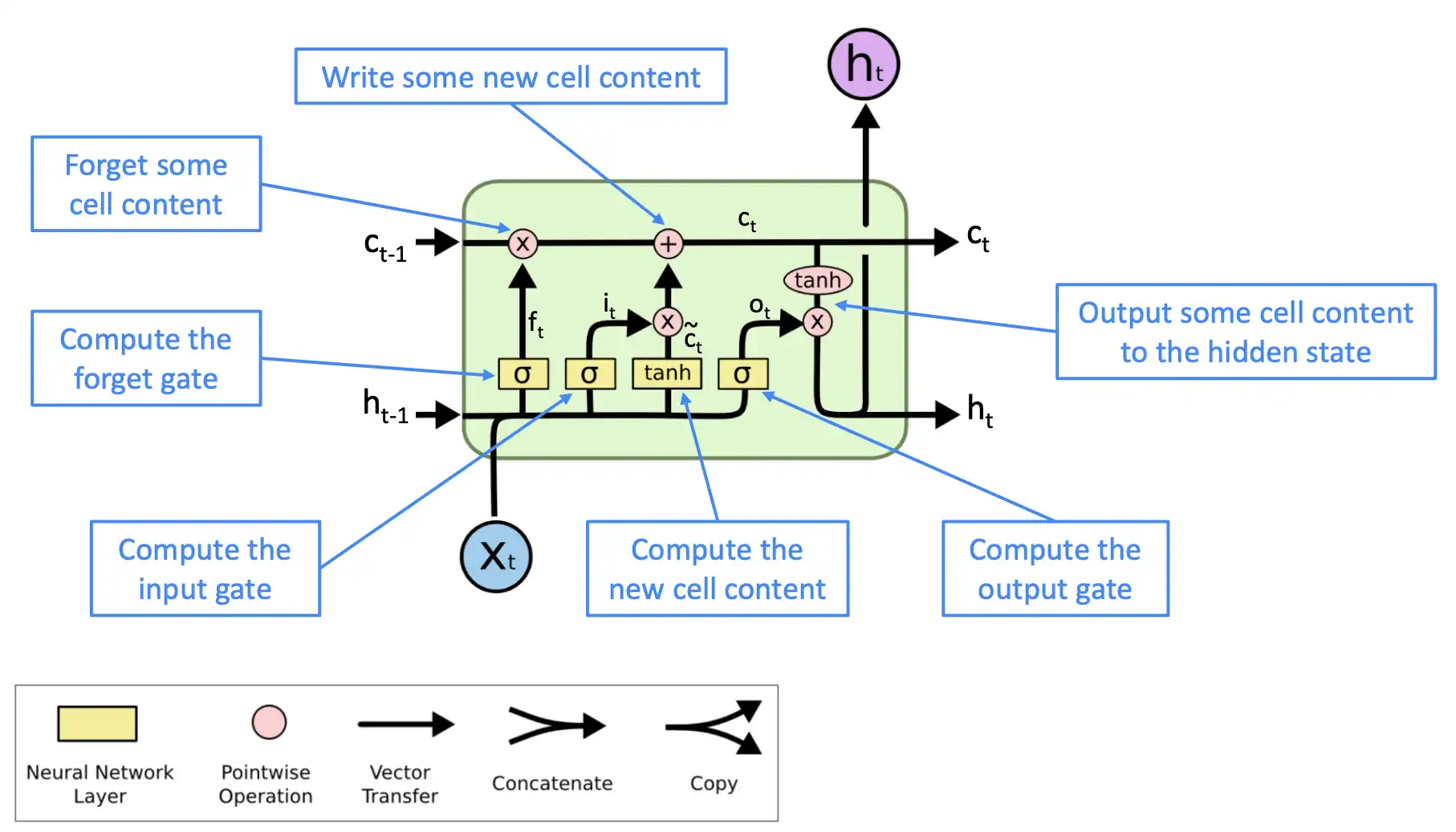
LSTM 模型在隐含层抽象出的门结构:
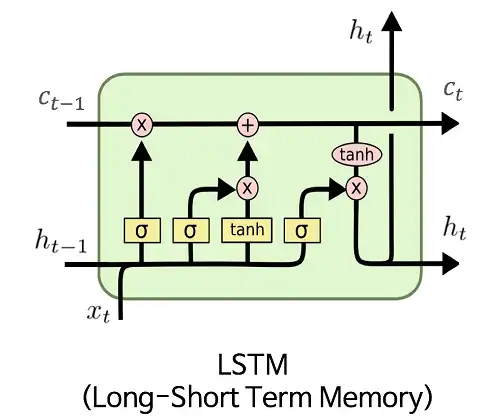

新增加的这 8个 参数分别为:输入门$ i(t) $、遗忘门$ f(t) $、输出门$ o(t) $和候选值向量$ g(t) $中$ X_t $的权重$ W_{i*} $与$ h_{t-1} $的权重$ W_{h*} $,其中 * 分别代表$ i、f、o和g $。
$$ i(t)=\sigma[W_{ii}X_t+W_{hi}h(t-1) + b_i ] $$
$$ f(t)=\sigma[W_{if}X_t+W_{hf}h(t-1) + b_f ] $$
$$ o(t)=\sigma[W_{io}X_t+W_{ho}h(t-1) + b_o ] $$
$$ g(t)=\tanh[W_{ig}X_t+W_{hg}h(t-1) + b_g ] $$
$$ c(t)=i(t)g(t) + f(t)c(t-1) $$
$$ h(t)=o(t)\tanh[c(t)] $$
上述6个计算公式中的偏置$ b_* $默认为0,在本文中的代码中不训练此参数,其中 * 分别代表$ i、f、o和g $。
4. 使用 RNN 模型进行序列生成
4-1. 引入相关包
# 导入程序需要用的包
# PyTorch 用的包
import torch
import torch.nn as nn
from torch.autograd import Variable
from collections import Counter #搜集器,可以让统计词频更简单
# 绘图、计算用的程序包
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rc
import numpy as np
# 将图形直接显示出来
%matplotlib inline4-2. 生成训练数据
首先设定控制生成字符串长度的概率
# 生成的样本数量
samples = 2000
# 训练样本中 n 的最大值
sz = 10
# 定义不用 n 的权重,我们按照 10:6:4:3:1:1...来配置字符串生成中的 n=1,2,3,4,5,...
probability = 1.0 * np.array([10, 6, 4, 3, 1, 1, 1, 1, 1, 1])
# 保证 n 的最大值为 sz
probability = probability[:sz]
# 归一化,将权重变成概率
probability = probability / sum(probability)接着生成训练数据集和校验数据集
train_set = []
# 开始生成 samples 个样本
for m in range(samples):
# 对于每一个生成的字符串,随机选择一个 n,n 被选择的权重被记录在 probability 中
n = np.random.choice(range(1, sz + 1), p = probability)
# 生成这个字符串,用 list 的形式完成记录
inputs = [0] * n + [1] * n
# 在最前面插入 3 表示起始字符,2 插入尾端表示终止字符
inputs.insert(0, 3)
inputs.append(2)
# 将生成的字符串加入到 train_set 训练集中
train_set.append(inputs)
valid_set = []
# 再生成 samples / 10 个校验样本
for m in range(samples // 10):
n = np.random.choice(range(1, sz + 1), p = probability)
inputs = [0] * n + [1] * n
inputs.insert(0, 3)
inputs.append(2)
valid_set.append(inputs)与训练数据集不同的是,我们会生成少量的超长序列,也就是 n 超大的序列在校验数据集中,用以考验模型的能力极限。
# 再生成若干 n 超大的校验样本
for m in range(2):
n = sz + m
inputs = [0] * n + [1] * n
inputs.insert(0, 3)
inputs.append(2)
valid_set.append(inputs)
np.random.shuffle(valid_set)4-3. 定义 RNN 模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.rnn = nn.RNN(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
x = self.embedding(input)
output, hidden = self.rnn(x, hidden)
output = output[:,-1,:]
output = self.fc(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return Variable(torch.zeros(self.num_layers, 1, self.hidden_size))4-4. 训练 RNN 模型
# 生成一个最简化的 RNN ,输入 size 为 4,可能值为 0,1,2,3,输出 size 为 3,可能值为 0,1,2
rnn = SimpleRNN(input_size=4, hidden_size=2, output_size=3)
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.001)
# 重复进行 50 次实验
num_epoch = 50
results = []
for epoch in range(num_epoch):
train_loss = 0
np.random.shuffle(train_set)
for i, seq in enumerate(train_set):
loss = 0
hidden = rnn.initHidden()
for t in range(len(seq) - 1):
x = Variable(torch.LongTensor([seq[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([seq[t + 1]]))
output, hidden = rnn(x, hidden)
loss += criterion(output, y)
loss = 1.0 * loss / len(seq)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss
if i > 0 and i % 500 == 0:
print('第{}轮,第{}个,训练 Loss:{:.2f}'.format(epoch,
i,
train_loss.data.numpy() / i
))
第0轮,第500个,训练 Loss:0.80
第0轮,第1000个,训练 Loss:0.71
第0轮,第1500个,训练 Loss:0.65
第1轮,第500个,训练 Loss:0.48
第1轮,第1000个,训练 Loss:0.47
第1轮,第1500个,训练 Loss:0.47
第2轮,第500个,训练 Loss:0.42
第2轮,第1000个,训练 Loss:0.42
第2轮,第1500个,训练 Loss:0.41
第3轮,第500个,训练 Loss:0.40
第3轮,第1000个,训练 Loss:0.39
第3轮,第1500个,训练 Loss:0.38
第4轮,第500个,训练 Loss:0.36
第4轮,第1000个,训练 Loss:0.36
第4轮,第1500个,训练 Loss:0.36
第5轮,第500个,训练 Loss:0.31
第5轮,第1000个,训练 Loss:0.32
第5轮,第1500个,训练 Loss:0.32
第6轮,第500个,训练 Loss:0.32
第6轮,第1000个,训练 Loss:0.31
第6轮,第1500个,训练 Loss:0.31
第7轮,第500个,训练 Loss:0.30
第7轮,第1000个,训练 Loss:0.30
第7轮,第1500个,训练 Loss:0.30
第8轮,第500个,训练 Loss:0.29
第8轮,第1000个,训练 Loss:0.29
第8轮,第1500个,训练 Loss:0.29
第9轮,第500个,训练 Loss:0.29
第9轮,第1000个,训练 Loss:0.29
第9轮,第1500个,训练 Loss:0.28
第10轮,第500个,训练 Loss:0.27
第10轮,第1000个,训练 Loss:0.27
第10轮,第1500个,训练 Loss:0.27
第11轮,第500个,训练 Loss:0.27
第11轮,第1000个,训练 Loss:0.27
第11轮,第1500个,训练 Loss:0.27
第12轮,第500个,训练 Loss:0.27
第12轮,第1000个,训练 Loss:0.27
第12轮,第1500个,训练 Loss:0.27
第13轮,第500个,训练 Loss:0.26
第13轮,第1000个,训练 Loss:0.26
第13轮,第1500个,训练 Loss:0.26
第14轮,第500个,训练 Loss:0.26
第14轮,第1000个,训练 Loss:0.26
第14轮,第1500个,训练 Loss:0.26
第15轮,第500个,训练 Loss:0.26
第15轮,第1000个,训练 Loss:0.26
第15轮,第1500个,训练 Loss:0.26
第16轮,第500个,训练 Loss:0.26
第16轮,第1000个,训练 Loss:0.25
第16轮,第1500个,训练 Loss:0.26
第17轮,第500个,训练 Loss:0.25
第17轮,第1000个,训练 Loss:0.25
第17轮,第1500个,训练 Loss:0.25
第18轮,第500个,训练 Loss:0.26
第18轮,第1000个,训练 Loss:0.25
第18轮,第1500个,训练 Loss:0.25
第19轮,第500个,训练 Loss:0.25
第19轮,第1000个,训练 Loss:0.25
第19轮,第1500个,训练 Loss:0.25
第20轮,第500个,训练 Loss:0.25
第20轮,第1000个,训练 Loss:0.25
第20轮,第1500个,训练 Loss:0.25
第21轮,第500个,训练 Loss:0.25
第21轮,第1000个,训练 Loss:0.25
第21轮,第1500个,训练 Loss:0.25
第22轮,第500个,训练 Loss:0.24
第22轮,第1000个,训练 Loss:0.25
第22轮,第1500个,训练 Loss:0.25
第23轮,第500个,训练 Loss:0.25
第23轮,第1000个,训练 Loss:0.24
第23轮,第1500个,训练 Loss:0.25
第24轮,第500个,训练 Loss:0.24
第24轮,第1000个,训练 Loss:0.25
第24轮,第1500个,训练 Loss:0.24
第25轮,第500个,训练 Loss:0.24
第25轮,第1000个,训练 Loss:0.24
第25轮,第1500个,训练 Loss:0.24
第26轮,第500个,训练 Loss:0.25
第26轮,第1000个,训练 Loss:0.24
第26轮,第1500个,训练 Loss:0.24
第27轮,第500个,训练 Loss:0.25
第27轮,第1000个,训练 Loss:0.24
第27轮,第1500个,训练 Loss:0.24
第28轮,第500个,训练 Loss:0.26
第28轮,第1000个,训练 Loss:0.25
第28轮,第1500个,训练 Loss:0.25
第29轮,第500个,训练 Loss:0.24
第29轮,第1000个,训练 Loss:0.25
第29轮,第1500个,训练 Loss:0.24
第30轮,第500个,训练 Loss:0.24
第30轮,第1000个,训练 Loss:0.24
第30轮,第1500个,训练 Loss:0.24
第31轮,第500个,训练 Loss:0.24
第31轮,第1000个,训练 Loss:0.24
第31轮,第1500个,训练 Loss:0.24
第32轮,第500个,训练 Loss:0.24
第32轮,第1000个,训练 Loss:0.24
第32轮,第1500个,训练 Loss:0.24
第33轮,第500个,训练 Loss:0.24
第33轮,第1000个,训练 Loss:0.24
第33轮,第1500个,训练 Loss:0.24
第34轮,第500个,训练 Loss:0.24
第34轮,第1000个,训练 Loss:0.24
第34轮,第1500个,训练 Loss:0.24
第35轮,第500个,训练 Loss:0.23
第35轮,第1000个,训练 Loss:0.24
第35轮,第1500个,训练 Loss:0.24
第36轮,第500个,训练 Loss:0.24
第36轮,第1000个,训练 Loss:0.24
第36轮,第1500个,训练 Loss:0.24
第37轮,第500个,训练 Loss:0.23
第37轮,第1000个,训练 Loss:0.23
第37轮,第1500个,训练 Loss:0.24
第38轮,第500个,训练 Loss:0.24
第38轮,第1000个,训练 Loss:0.23
第38轮,第1500个,训练 Loss:0.24
第39轮,第500个,训练 Loss:0.24
第39轮,第1000个,训练 Loss:0.24
第39轮,第1500个,训练 Loss:0.24
第40轮,第500个,训练 Loss:0.24
第40轮,第1000个,训练 Loss:0.24
第40轮,第1500个,训练 Loss:0.24
第41轮,第500个,训练 Loss:0.24
第41轮,第1000个,训练 Loss:0.24
第41轮,第1500个,训练 Loss:0.24
第42轮,第500个,训练 Loss:0.23
第42轮,第1000个,训练 Loss:0.24
第42轮,第1500个,训练 Loss:0.24
第43轮,第500个,训练 Loss:0.24
第43轮,第1000个,训练 Loss:0.24
第43轮,第1500个,训练 Loss:0.24
第44轮,第500个,训练 Loss:0.23
第44轮,第1000个,训练 Loss:0.23
第44轮,第1500个,训练 Loss:0.24
第45轮,第500个,训练 Loss:0.24
第45轮,第1000个,训练 Loss:0.24
第45轮,第1500个,训练 Loss:0.23
第46轮,第500个,训练 Loss:0.23
第46轮,第1000个,训练 Loss:0.24
第46轮,第1500个,训练 Loss:0.24
第47轮,第500个,训练 Loss:0.24
第47轮,第1000个,训练 Loss:0.24
第47轮,第1500个,训练 Loss:0.24
第48轮,第500个,训练 Loss:0.23
第48轮,第1000个,训练 Loss:0.24
第48轮,第1500个,训练 Loss:0.24
第49轮,第500个,训练 Loss:0.24
第49轮,第1000个,训练 Loss:0.24
第49轮,第1500个,训练 Loss:0.24# 在校验集上测试
valid_loss = 0
errors = 0
show_out = ''
for i, seq in enumerate(valid_set):
loss = 0
outstring = ''
targets = ''
diff = 0
hidden = rnn.initHidden()
for t in range(len(seq) - 1):
x = Variable(torch.LongTensor([seq[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([seq[t + 1]]))
output, hidden = rnn(x, hidden)
mm = torch.max(output, 1)[1][0]
outstring += str(mm.data.numpy())
targets += str(y.data.numpy()[0])
loss += criterion(output, y)
diff += 1 - mm.eq(y).data.numpy()[0]
loss = 1.0 * loss / len(seq)
valid_loss += loss
errors += diff
if np.random.rand() < 0.1:
show_out = outstring + '\n' + targets
# print(output[0][5].data.numpy())
print('第{}轮,训练 Loss:{:.2f},校验 Loss:{:.2f},错误率:{:.2f}'.format(epoch,
train_loss.data.numpy() / len(train_set),
valid_loss.data.numpy() / len(valid_set),
1.0 * errors / len(valid_set)
))
# print(show_out)
results.append([train_loss.data.numpy() / len(train_set),
valid_loss.data.numpy() / len(valid_set),
1.0 * errors / len(valid_set)])
第49轮,训练 Loss:0.23,校验 Loss:0.26,错误率:1.51
# 保存模型
torch.save(rnn, './模型/8.nLp/rnn.mdl')4-5. 观察 RNN 模型的学习结果
for n in range(20):
inputs = [0] * n + [1] * n
inputs.insert(0, 3)
inputs.append(2)
outstring = ''
targets = ''
diff = 0
hiddens = []
hidden = rnn.initHidden()
for t in range(len(inputs) - 1):
x = Variable(torch.LongTensor([inputs[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([inputs[t + 1]]))
output, hidden = rnn(x, hidden)
hiddens.append(hidden.data.numpy()[0][0])
mm = torch.max(output, 1)[1][0]
outstring += str(mm.data.numpy())
targets += str(y.data.numpy()[0])
diff += 1 - mm.eq(y).data.numpy()[0]
print(outstring)
print(targets)
print('Diff:{}'.format(diff))
0
2
Diff:1
012
012
Diff:0
01012
00112
Diff:2
0100112
0001112
Diff:2
010001112
000011112
Diff:2
01000011112
00000111112
Diff:2
0100000111112
0000001111112
Diff:2
010000001111111
000000011111112
Diff:3
01000000011111112
00000000111111112
Diff:2
0100000000111111111
0000000001111111112
Diff:3
010000000001111111212
000000000011111111112
Diff:3
01000000000011111111111
00000000000111111111112
Diff:3
0100000000000111111111212
0000000000001111111111112
Diff:3
010000000000001111111111121
000000000000011111111111112
Diff:4
01000000000000011111111121212
00000000000000111111111111112
Diff:4
0100000000000000111111111112121
0000000000000001111111111111112
Diff:5
010000000000000001111111112121212
000000000000000011111111111111112
Diff:5
01000000000000000011111111111212121
00000000000000000111111111111111112
Diff:6
0100000000000000000111111111212121212
0000000000000000001111111111111111112
Diff:6
010000000000000000001111111111121212121
000000000000000000011111111111111111112
Diff:75. 使用 LSTM 模型进行序列生成
5-1. 定义 LSTM 模型
class SimpleLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
x = self.embedding(input)
output, hidden = self.lstm(x, hidden)
output = output[:,-1,:]
output = self.fc(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
hidden = Variable(torch.zeros(self.num_layers, 1, self.hidden_size))
cell = Variable(torch.zeros(self.num_layers, 1, self.hidden_size))
return (hidden, cell)5-2. 训练 LSTM 模型
# 生成一个 LSTM ,输入 size 为 4,可能值为 0,1,2,3,输出 size 为 3,可能值为 0,1,2
lstm = SimpleLSTM(input_size=4, hidden_size=2, output_size=3)
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.Adam(lstm.parameters(), lr=0.001)
# 重复进行 50 次实验
num_epoch = 50
results = []
for epoch in range(num_epoch):
train_loss = 0
np.random.shuffle(train_set)
for i, seq in enumerate(train_set):
loss = 0
hidden = lstm.initHidden()
for t in range(len(seq) - 1):
x = Variable(torch.LongTensor([seq[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([seq[t + 1]]))
output, hidden = lstm(x, hidden)
loss += criterion(output, y)
loss = 1.0 * loss / len(seq)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss
if i > 0 and i % 500 == 0:
print('第{}轮,第{}个,训练 Loss:{:.2f}'.format(epoch,
i,
train_loss.data.numpy() / i
))
第0轮,第500个,训练 Loss:0.87
第0轮,第1000个,训练 Loss:0.81
第0轮,第1500个,训练 Loss:0.76
第1轮,第500个,训练 Loss:0.53
第1轮,第1000个,训练 Loss:0.52
第1轮,第1500个,训练 Loss:0.51
第2轮,第500个,训练 Loss:0.44
第2轮,第1000个,训练 Loss:0.43
第2轮,第1500个,训练 Loss:0.42
第3轮,第500个,训练 Loss:0.33
第3轮,第1000个,训练 Loss:0.32
第3轮,第1500个,训练 Loss:0.31
第4轮,第500个,训练 Loss:0.27
第4轮,第1000个,训练 Loss:0.26
第4轮,第1500个,训练 Loss:0.26
第5轮,第500个,训练 Loss:0.25
第5轮,第1000个,训练 Loss:0.24
第5轮,第1500个,训练 Loss:0.25
第6轮,第500个,训练 Loss:0.24
第6轮,第1000个,训练 Loss:0.24
第6轮,第1500个,训练 Loss:0.24
第7轮,第500个,训练 Loss:0.24
第7轮,第1000个,训练 Loss:0.24
第7轮,第1500个,训练 Loss:0.24
第8轮,第500个,训练 Loss:0.23
第8轮,第1000个,训练 Loss:0.24
第8轮,第1500个,训练 Loss:0.23
第9轮,第500个,训练 Loss:0.24
第9轮,第1000个,训练 Loss:0.23
第9轮,第1500个,训练 Loss:0.23
第10轮,第500个,训练 Loss:0.23
第10轮,第1000个,训练 Loss:0.23
第10轮,第1500个,训练 Loss:0.23
第11轮,第500个,训练 Loss:0.23
第11轮,第1000个,训练 Loss:0.23
第11轮,第1500个,训练 Loss:0.23
第12轮,第500个,训练 Loss:0.23
第12轮,第1000个,训练 Loss:0.23
第12轮,第1500个,训练 Loss:0.23
第13轮,第500个,训练 Loss:0.23
第13轮,第1000个,训练 Loss:0.23
第13轮,第1500个,训练 Loss:0.23
第14轮,第500个,训练 Loss:0.23
第14轮,第1000个,训练 Loss:0.23
第14轮,第1500个,训练 Loss:0.23
第15轮,第500个,训练 Loss:0.23
第15轮,第1000个,训练 Loss:0.23
第15轮,第1500个,训练 Loss:0.23
第16轮,第500个,训练 Loss:0.23
第16轮,第1000个,训练 Loss:0.23
第16轮,第1500个,训练 Loss:0.23
第17轮,第500个,训练 Loss:0.23
第17轮,第1000个,训练 Loss:0.23
第17轮,第1500个,训练 Loss:0.23
第18轮,第500个,训练 Loss:0.23
第18轮,第1000个,训练 Loss:0.23
第18轮,第1500个,训练 Loss:0.23
第19轮,第500个,训练 Loss:0.23
第19轮,第1000个,训练 Loss:0.23
第19轮,第1500个,训练 Loss:0.23
第20轮,第500个,训练 Loss:0.23
第20轮,第1000个,训练 Loss:0.23
第20轮,第1500个,训练 Loss:0.23
第21轮,第500个,训练 Loss:0.23
第21轮,第1000个,训练 Loss:0.23
第21轮,第1500个,训练 Loss:0.23
第22轮,第500个,训练 Loss:0.23
第22轮,第1000个,训练 Loss:0.23
第22轮,第1500个,训练 Loss:0.23
第23轮,第500个,训练 Loss:0.23
第23轮,第1000个,训练 Loss:0.23
第23轮,第1500个,训练 Loss:0.23
第24轮,第500个,训练 Loss:0.23
第24轮,第1000个,训练 Loss:0.23
第24轮,第1500个,训练 Loss:0.23
第25轮,第500个,训练 Loss:0.23
第25轮,第1000个,训练 Loss:0.23
第25轮,第1500个,训练 Loss:0.23
第26轮,第500个,训练 Loss:0.23
第26轮,第1000个,训练 Loss:0.23
第26轮,第1500个,训练 Loss:0.23
第27轮,第500个,训练 Loss:0.23
第27轮,第1000个,训练 Loss:0.23
第27轮,第1500个,训练 Loss:0.23
第28轮,第500个,训练 Loss:0.23
第28轮,第1000个,训练 Loss:0.23
第28轮,第1500个,训练 Loss:0.23
第29轮,第500个,训练 Loss:0.23
第29轮,第1000个,训练 Loss:0.23
第29轮,第1500个,训练 Loss:0.23
第30轮,第500个,训练 Loss:0.23
第30轮,第1000个,训练 Loss:0.23
第30轮,第1500个,训练 Loss:0.23
第31轮,第500个,训练 Loss:0.23
第31轮,第1000个,训练 Loss:0.23
第31轮,第1500个,训练 Loss:0.23
第32轮,第500个,训练 Loss:0.23
第32轮,第1000个,训练 Loss:0.23
第32轮,第1500个,训练 Loss:0.23
第33轮,第500个,训练 Loss:0.23
第33轮,第1000个,训练 Loss:0.23
第33轮,第1500个,训练 Loss:0.23
第34轮,第500个,训练 Loss:0.23
第34轮,第1000个,训练 Loss:0.23
第34轮,第1500个,训练 Loss:0.23
第35轮,第500个,训练 Loss:0.23
第35轮,第1000个,训练 Loss:0.23
第35轮,第1500个,训练 Loss:0.23
第36轮,第500个,训练 Loss:0.23
第36轮,第1000个,训练 Loss:0.23
第36轮,第1500个,训练 Loss:0.23
第37轮,第500个,训练 Loss:0.23
第37轮,第1000个,训练 Loss:0.23
第37轮,第1500个,训练 Loss:0.23
第38轮,第500个,训练 Loss:0.23
第38轮,第1000个,训练 Loss:0.23
第38轮,第1500个,训练 Loss:0.23
第39轮,第500个,训练 Loss:0.23
第39轮,第1000个,训练 Loss:0.23
第39轮,第1500个,训练 Loss:0.23
第40轮,第500个,训练 Loss:0.23
第40轮,第1000个,训练 Loss:0.23
第40轮,第1500个,训练 Loss:0.23
第41轮,第500个,训练 Loss:0.23
第41轮,第1000个,训练 Loss:0.23
第41轮,第1500个,训练 Loss:0.23
第42轮,第500个,训练 Loss:0.23
第42轮,第1000个,训练 Loss:0.23
第42轮,第1500个,训练 Loss:0.23
第43轮,第500个,训练 Loss:0.23
第43轮,第1000个,训练 Loss:0.23
第43轮,第1500个,训练 Loss:0.23
第44轮,第500个,训练 Loss:0.23
第44轮,第1000个,训练 Loss:0.23
第44轮,第1500个,训练 Loss:0.23
第45轮,第500个,训练 Loss:0.23
第45轮,第1000个,训练 Loss:0.23
第45轮,第1500个,训练 Loss:0.23
第46轮,第500个,训练 Loss:0.23
第46轮,第1000个,训练 Loss:0.23
第46轮,第1500个,训练 Loss:0.23
第47轮,第500个,训练 Loss:0.23
第47轮,第1000个,训练 Loss:0.23
第47轮,第1500个,训练 Loss:0.23
第48轮,第500个,训练 Loss:0.23
第48轮,第1000个,训练 Loss:0.23
第48轮,第1500个,训练 Loss:0.23
第49轮,第500个,训练 Loss:0.23
第49轮,第1000个,训练 Loss:0.23
第49轮,第1500个,训练 Loss:0.23# 在校验集上测试
valid_loss = 0
errors = 0
show_out = ''
for i, seq in enumerate(valid_set):
loss = 0
outstring = ''
targets = ''
diff = 0
hidden = lstm.initHidden()
for t in range(len(seq) - 1):
x = Variable(torch.LongTensor([seq[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([seq[t + 1]]))
output, hidden = lstm(x, hidden)
mm = torch.max(output, 1)[1][0]
outstring += str(mm.data.numpy())
targets += str(y.data.numpy()[0])
loss += criterion(output, y)
diff += 1 - mm.eq(y).data.numpy()[0]
loss = 1.0 * loss / len(seq)
valid_loss += loss
errors += diff
if np.random.rand() < 0.1:
show_out = outstring + '\n' + targets
# print(output[0][6].data.numpy())
print('第{}轮,训练 Loss:{:.2f},校验 Loss:{:.2f},错误率:{:.2f}'.format(epoch,
train_loss.data.numpy() / len(train_set),
valid_loss.data.numpy() / len(valid_set),
1.0 * errors / len(valid_set)
))
# print(show_out)
results.append([train_loss.data.numpy() / len(train_set),
valid_loss.data.numpy() / len(valid_set),
1.0 * errors / len(valid_set)])
第49轮,训练 Loss:0.23,校验 Loss:0.24,错误率:1.43
results[[0.22905935668945313, 0.2386343549973894, 1.4257425742574257]]
# 保存模型
torch.save(lstm, './模型/8.nLp/lstm.mdl')5-3. 观察 LSTM 模型的学习结果
for n in range(20):
inputs = [0] * n + [1] * n
inputs.insert(0, 3)
inputs.append(2)
outstring = ''
targets = ''
diff = 0
hiddens = []
hidden = lstm.initHidden()
for t in range(len(inputs) - 1):
x = Variable(torch.LongTensor([inputs[t]]).unsqueeze(0))
y = Variable(torch.LongTensor([inputs[t + 1]]))
output, hidden = lstm(x, hidden)
mm = torch.max(output, 1)[1][0]
outstring += str(mm.data.numpy())
targets += str(y.data.numpy()[0])
diff += 1 - mm.eq(y).data.numpy()[0]
print(n)
print(outstring)
print(targets)
print('Diff:{}'.format(diff))
0
0
2
Diff:1
1
012
012
Diff:0
2
01012
00112
Diff:2
3
0100112
0001112
Diff:2
4
010001112
000011112
Diff:2
5
01000011112
00000111112
Diff:2
6
0100000111112
0000001111112
Diff:2
7
010000001111112
000000011111112
Diff:2
8
01000000011111112
00000000111111112
Diff:2
9
0100000000111111112
0000000001111111112
Diff:2
10
010000000001111111112
000000000011111111112
Diff:2
11
01000000000011111111112
00000000000111111111112
Diff:2
12
0100000000000111111111112
0000000000001111111111112
Diff:2
13
010000000000001111111111122
000000000000011111111111112
Diff:3
14
01000000000000011111111111122
00000000000000111111111111112
Diff:3
15
0100000000000000111111111111122
0000000000000001111111111111112
Diff:3
16
010000000000000001111111111111222
000000000000000011111111111111112
Diff:4
17
01000000000000000011111111111111222
00000000000000000111111111111111112
Diff:4
18
0100000000000000000111111111111111222
0000000000000000001111111111111111112
Diff:4
19
010000000000000000001111111111111112222
000000000000000000011111111111111111112
Diff:56. 小结
最终的训练 Loss:0.23,校验 Loss:0.26,错误率:1.51;
最终的训练 Loss:0.23,校验 Loss:0.24,错误率:1.43。

